Online Compaction: Overview
This feature is currently in Private Preview.
- Must be enabled by Tecton Support.
- Available for Spark-based Feature Views -- coming to Rift in a future release.
- See additional limitations & requirements below.
Online compaction is a new supported mode for Tecton’s Aggregation Engine. When enabled for Batch or Stream Feature Views, online compaction can lead to substantially reduced costs and improve performance for online serving. Online compaction enables Tecton to efficiently support extremely long-windowed and lifetime (i.e. unbounded) aggregations, even for applications with extremely high-volume streams and demanding data-freshness requirements.
This doc provides a conceptual and architectural overview for online compaction: what it is, how it works, etc. For details about how to configure and use online compaction, see this guide.
This article covers the online compaction mode for Tecton’s Aggregation Engine. If you’d like to understand how Tecton’s Aggregation Engine works without online compaction, then see this article
Background Terminology and Concepts
Data Compaction: the process of reducing the amount of stored data in a data system while maintaining its essential information needed for expected retrieval patterns.
Partial-Aggregate Tile: a unit of compacted data used in aggregations. Tiles may be combined and finalized into aggregation results. Tiles may be simple data types (e.g. an integer for a count or sum) or complex data structures (e.g. for sketch algorithms like HyperLogLog).
Lifetime Aggregation: an unbounded aggregation window, for example a user’s lifetime spend on an e-commerce site.
Lambda Architecture: a data-processing architecture that hybridizes batch and stream compute to take advantages of both strength’s for performant, cost-effective, high-scale applications.
Batch Healing: the process of cleaning or “healing” production data systems with cleaner batch data. For example, updating video view counts or product ratings after a next-day, batch defrauding and deduping process.
Online Compaction Architecture
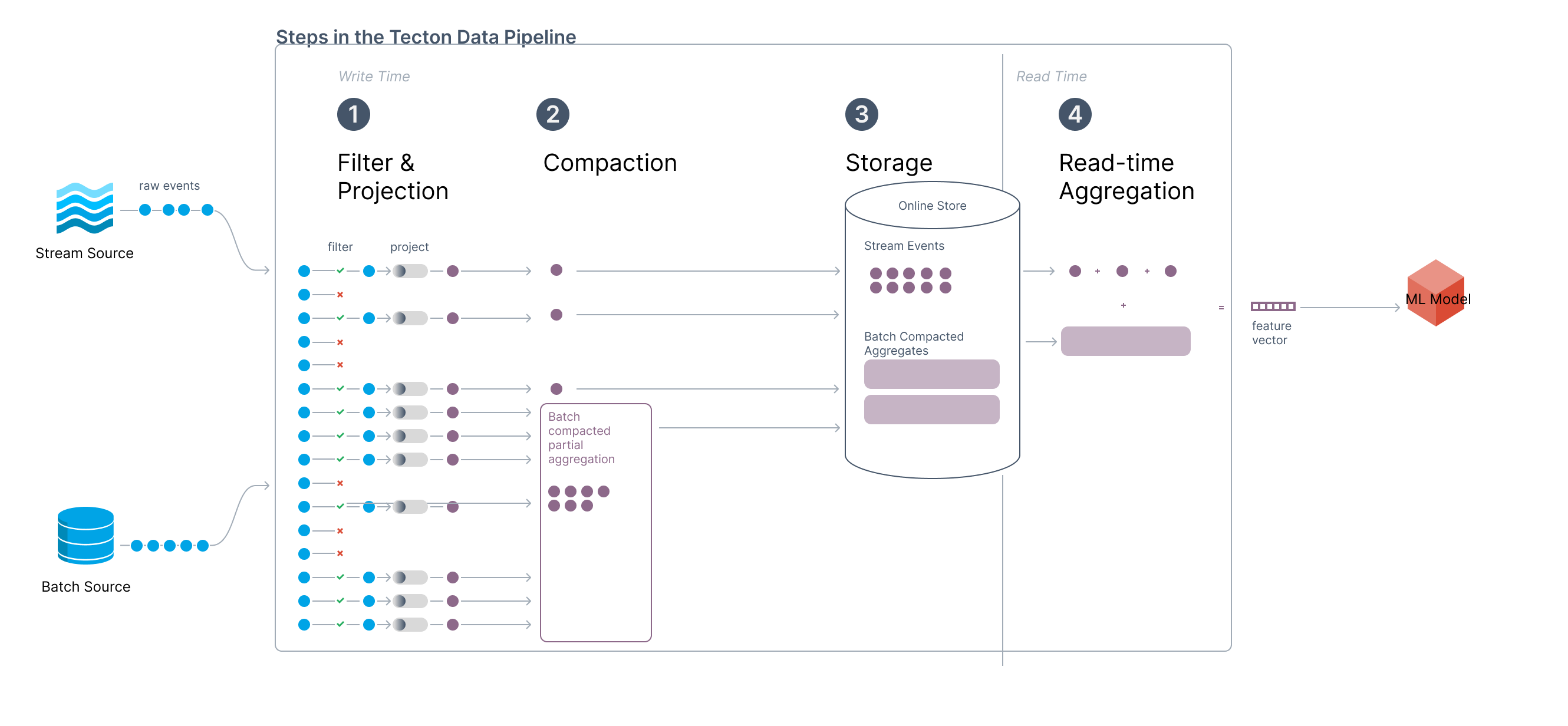 Architecture for a Streaming Lifetime Aggregation
Architecture for a Streaming Lifetime Aggregation
The above architecture shows how Tecton implements streaming lifetime aggregations. This architecture takes advantage of both batch and stream updates to the online store.
Batch Updates to the Online Store
-
On a pre-defined cadence – typically daily – Tecton will rebuild tiles in the Online Store based on data available in the Offline Store. A batch job will read the offline data for the full aggregation window, perform the aggregations, and update the Online Store for each entity. Tecton refers to this process as the compaction job.
-
To avoid expensive write operations, Tecton leverages DynamoDB’s S3 Bulk Import functionality to write to the Online Store during the compaction job. The bulk import functionality makes both backfills and daily updates cheap even for high-volume data. More information on cost savings can be found here.
Stream Updates to the Online Store
- Streaming events are written to the Online Store as they arrive in the stream. This ensures that Tecton uses the most recent data possible during retrieval.
At read time, Tecton combines the most recent streaming events with the large “compacted” tile written by the batch job to obtain the final aggregation value.
This architecture allows Tecton to significantly reduce the amount of data processed at read time, especially for long aggregation windows. Instead of aggregating over all the historical data, Tecton only needs to read at most only ~1 day's worth of streaming data and the 1 large compacted tile. This architecture is particularly useful for lifetime or long-windowed aggregations that can span over years of data.
Additionally, Tecton’s compaction job allows for batch healing since each compaction job recreates the entire Online Store. If incorrect data is materialized, it can be easily corrected by batch data during the next compaction job.
Batch-only Features
For non-streaming features, the architecture looks the same minus the streaming job. At read time, Tecton simply reads the fully aggregated feature value that was written by the last compaction job. This approach is extremely cost-efficient and is recommended for use cases that don’t need streaming freshness.
Scale Streaming Further with Stream Tiling
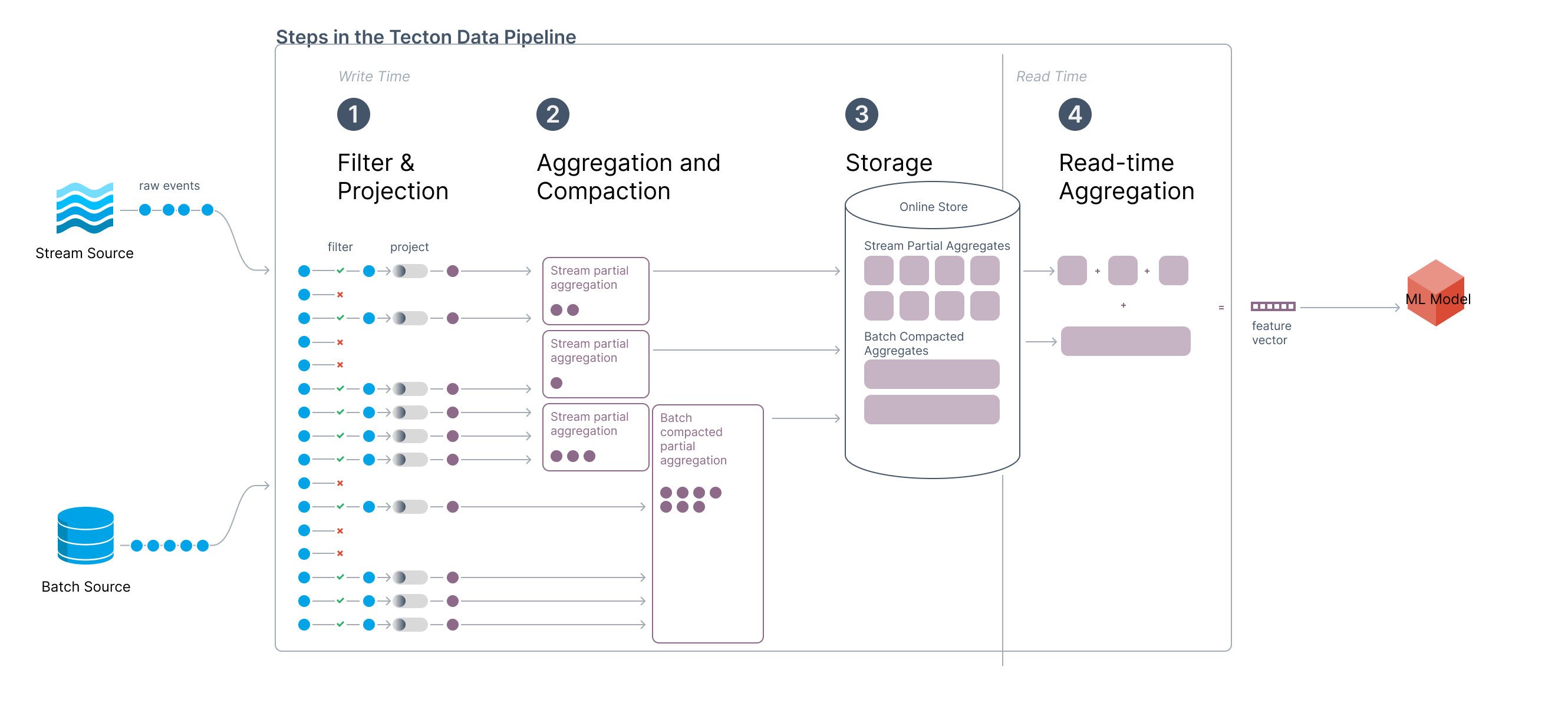 Architecture for a Streaming Lifetime Aggregation with Stream Tiling
Architecture for a Streaming Lifetime Aggregation with Stream Tiling
For streams with hot keys (i.e. keys with a high frequency of incoming events) aggregating over even 24 hours of stream data can cause poor performance at read time. Tecton’s solution to this problem is stream tiling.
Stream tiling can be thought of as also compacting the streaming data that is written to the online store. Instead of writing stream events directly to the online store, Tecton takes advantage of stateful stream processors to pre-aggregate (or compact) the streaming data into tiles. This takes the worst-case retrieval and storage performance per key from O(n) to O(1).
Performant Window Aggregations
So far, we’ve only discussed lifetime windows. Window aggregations, i.e. aggregations over a relative window like the count of user engagements over a rolling 7-day window, can also benefit substantially from online compaction but require a slightly more advanced approach.
Background: Sliding, Hopping, and Sawtooth Windows
In order to support window aggregations that are both fresh (i.e. use the very latest ingested data) and very performant, Tecton uses an approach to relative windowing called "Sawtooth Windowing". For background, this section covers the other common windowing approaches used in real-time and streaming applications. These approaches differ on how they advance the aggregation window with respect to wall-clock time and have different performance, freshness, and accuracy tradeoffs.
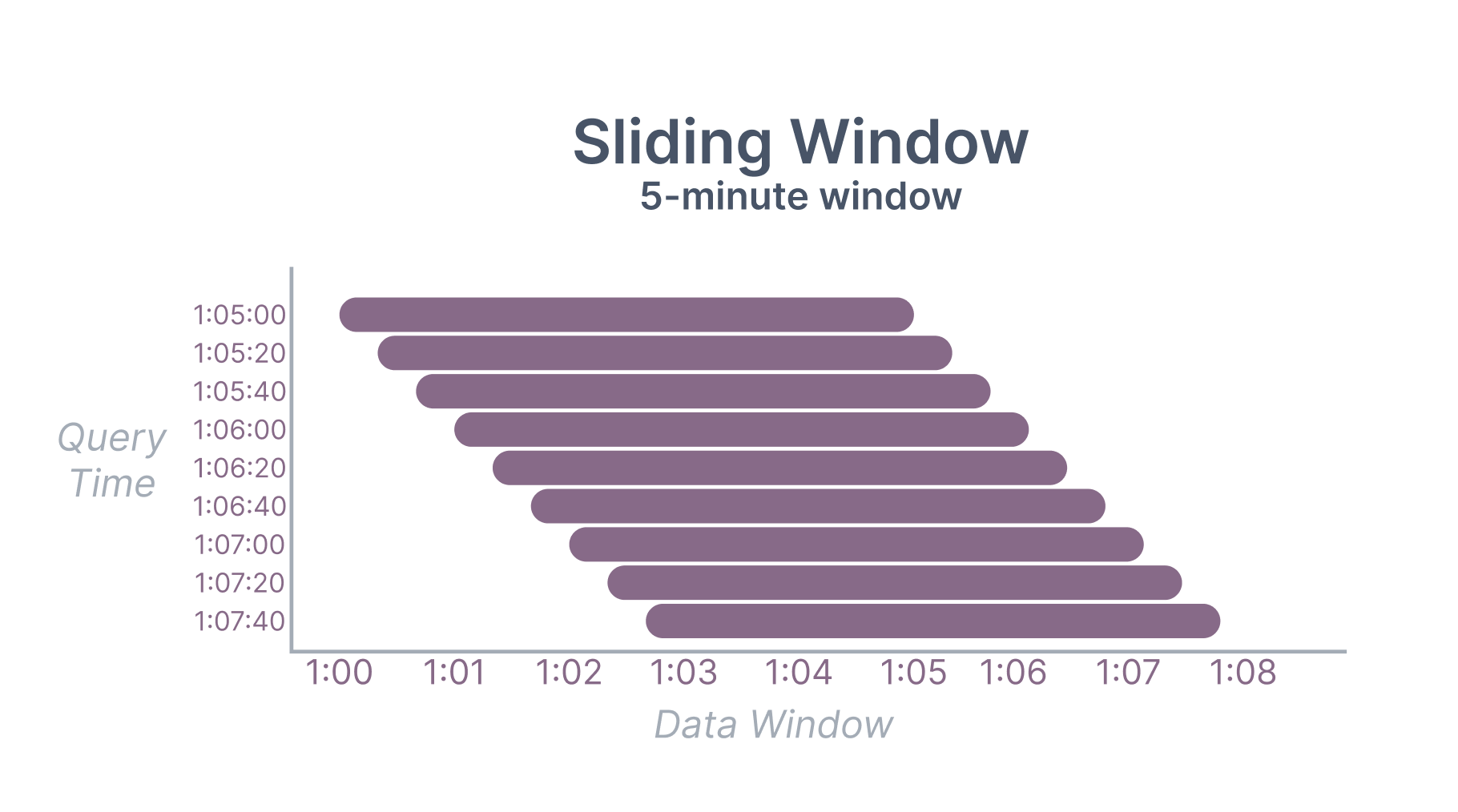
A sliding window is always a fixed width and advances continuously. For example, a five-minute sliding window queried at 1:05:20 would aggregate over the range (1:00:20, 1:05:20].
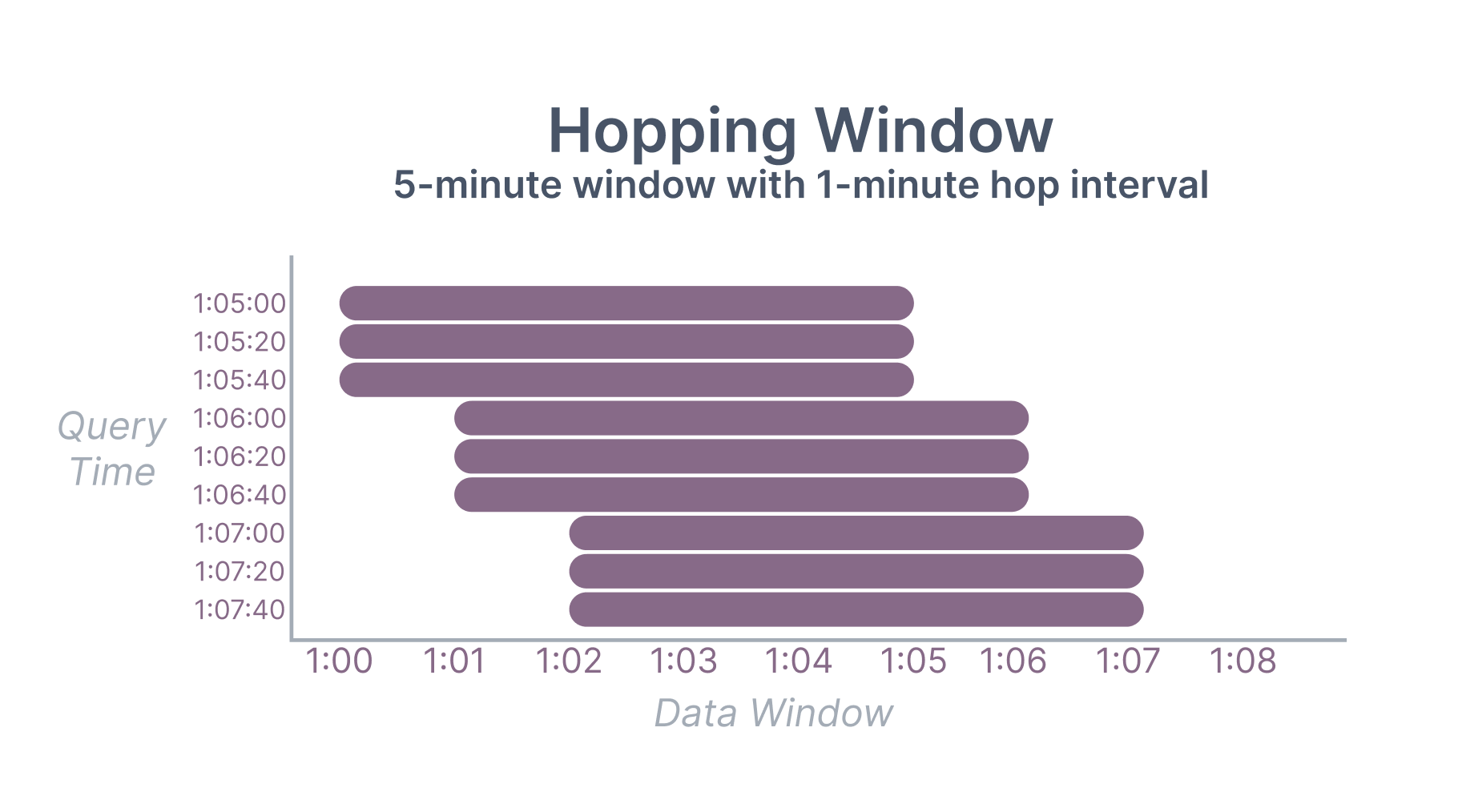
A hopping window is also always a fixed width but advances at fixed intervals. For example, a five-minute hopping window with a 1-minute interval queried at 1:05:20 would aggregate over the range (1:00:00, 1:05:00]. Hopping windows can be more performant than sliding windows (because data can be tiled to the interval size) but come at the cost of a freshness delay.
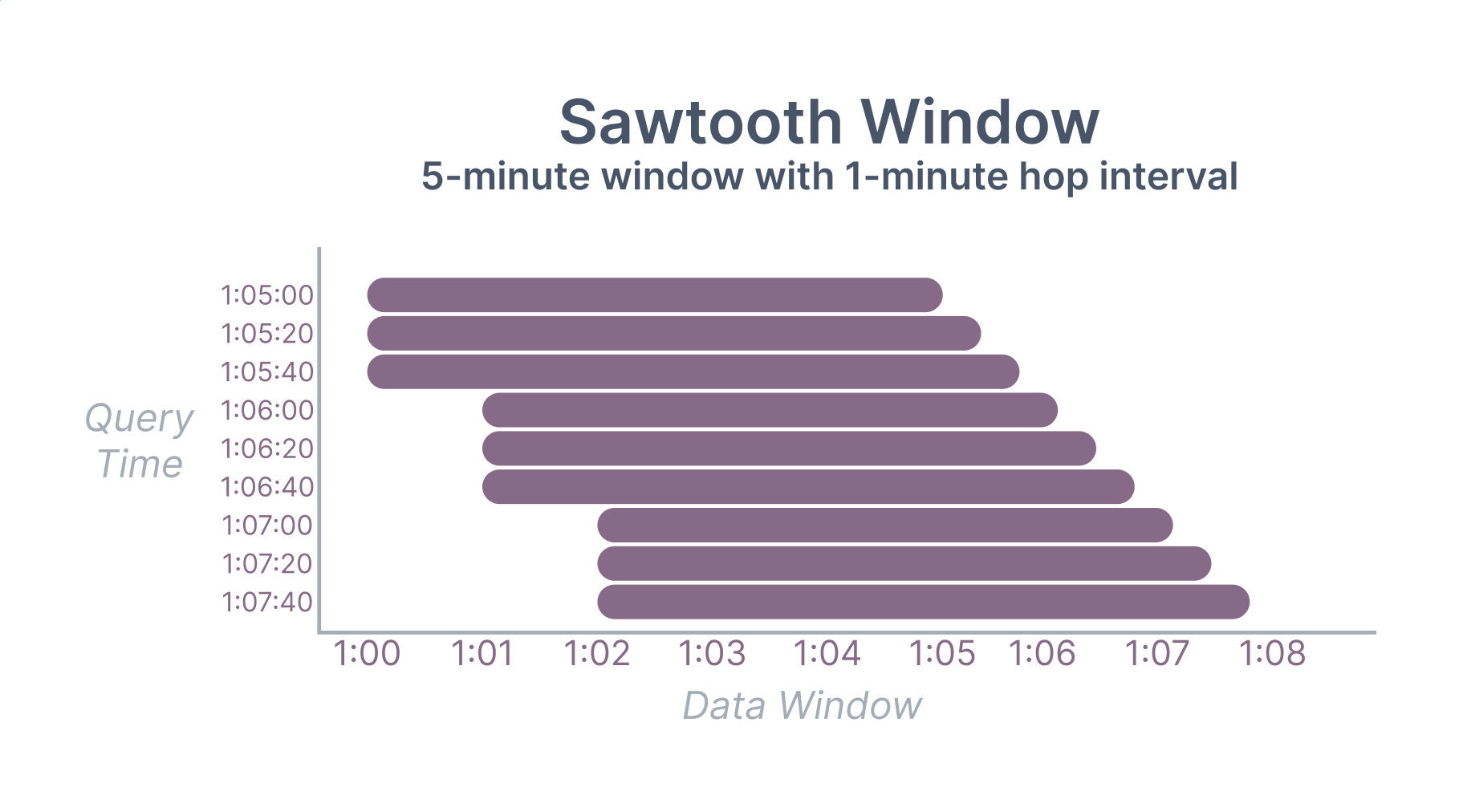
A sawtooth window is a combination of a sliding and hopping window. The leading edge of a sawtooth window advances continuously like a sliding window but the trailing edge advances at fixed intervals like a hopping window. This means that a sawtooth window is not a fixed width. For example, a five-minute sawtooth window with a 1-minute interval queried at 1:05:20 would aggregate over the range (1:00:00, 1:05:20].
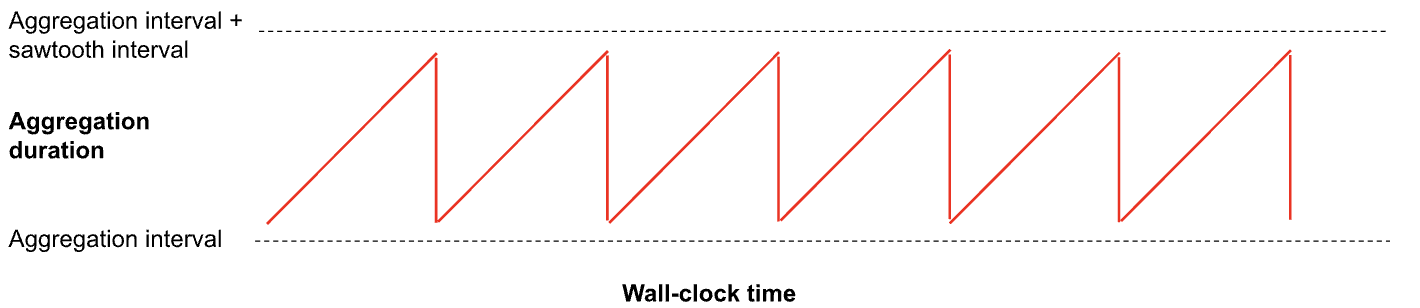 Visualization of
a sawtooth aggregate value over time. Looks like teeth on a saw.
Visualization of
a sawtooth aggregate value over time. Looks like teeth on a saw.
Sawtooth windows can achieve the performance of hopping windows and the freshness of sliding window. The tradeoff is that sawtooth windows introduce some fuzziness in the window width. For most AI applications, the tradeoff of a 1-10% window fuzziness is well worth the performance and freshness benefits.
Tecton uses sawtooth windowing with online compaction to support extremely performant and fresh aggregations. Tecton also ensures that the fuzziness of sawtooth windowing is reliably reflected in training data generated with Tecton.
Window Aggregate Architecture
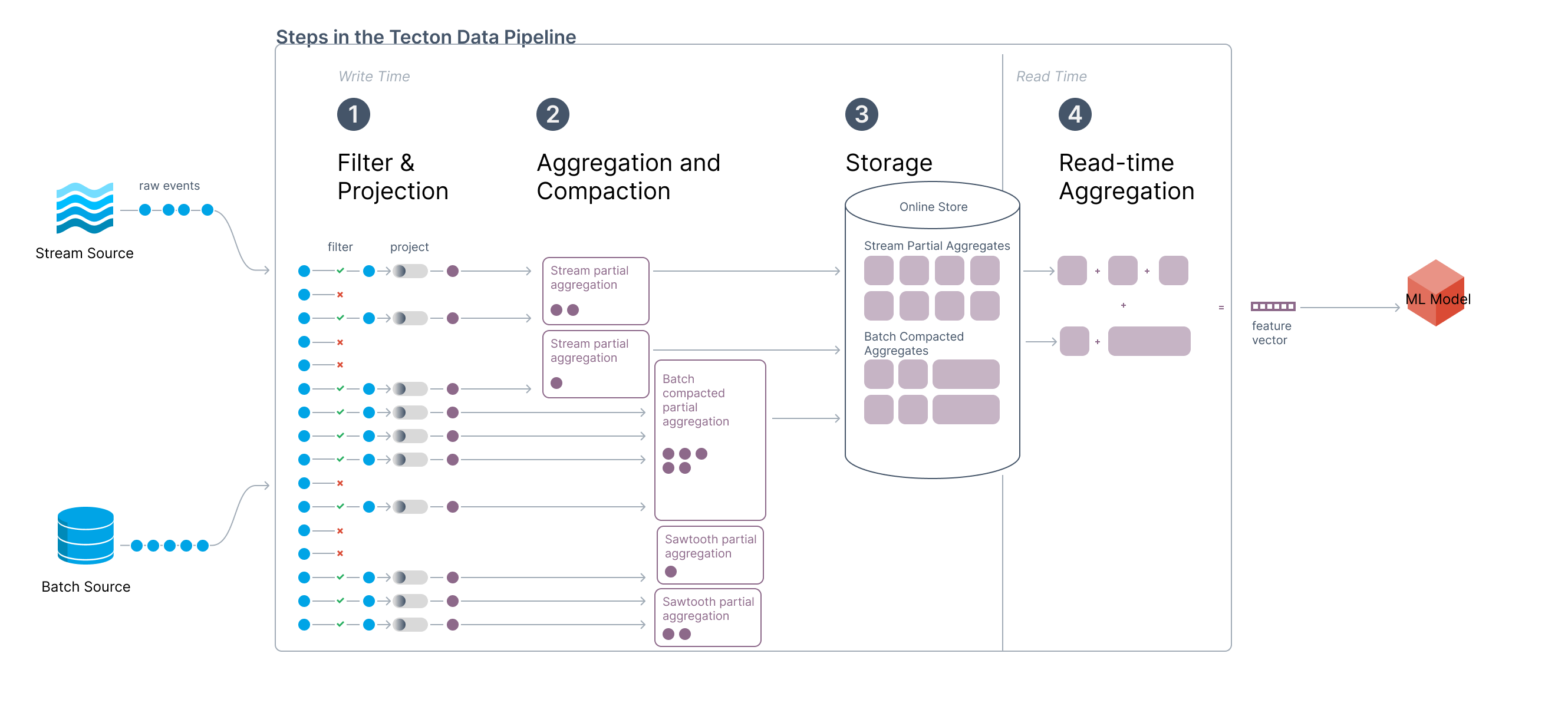 Architecture for a Streaming Window Aggregation
Architecture for a Streaming Window Aggregation
To efficiently implement sawtooth windowing, the compaction job computes partial aggregations to create a few number of small tiles at the tail (i.e. the oldest edge) of the aggregation window in addition to a larger compacted tile. We refer to these small tail tiles as the “sawtooth” tiles. For example, for a 30-day window, the large compacted tile could be 28 days with 48 one-hour sawtooth tiles. The ideal size of these sawtooth tiles is a tradeoff between storage efficiency and tolerated fuzziness.
As time progresses between compaction jobs, Tecton will read more stream events at the head of the window and drop sawtooth tiles from the tail of the window. Reading the latest stream events guarantees fresh data while hopping the tail of the window allows for efficient storage and reads.
Batch-only Features
Non-streaming time window aggregations do not use sawtooth aggregations. The compaction job writes 1 tile representing the fully aggregated feature value on the batch materialization schedule. The aggregation window progresses forward during each compaction job. This approach is extremely cost-efficient and is recommended for use cases that don’t need streaming freshness.
Materialization, Offline Store, and Batch Retrieval
Up to this point, this article has primarily focused on online materialization and serving. This section covers how Tecton sequences batch jobs, materializes data to the offline store, and retrieves offline data for training data generation.
When online compaction is enabled, Tecton uses multiple batch job stages to materialize data to the offline and online stores.
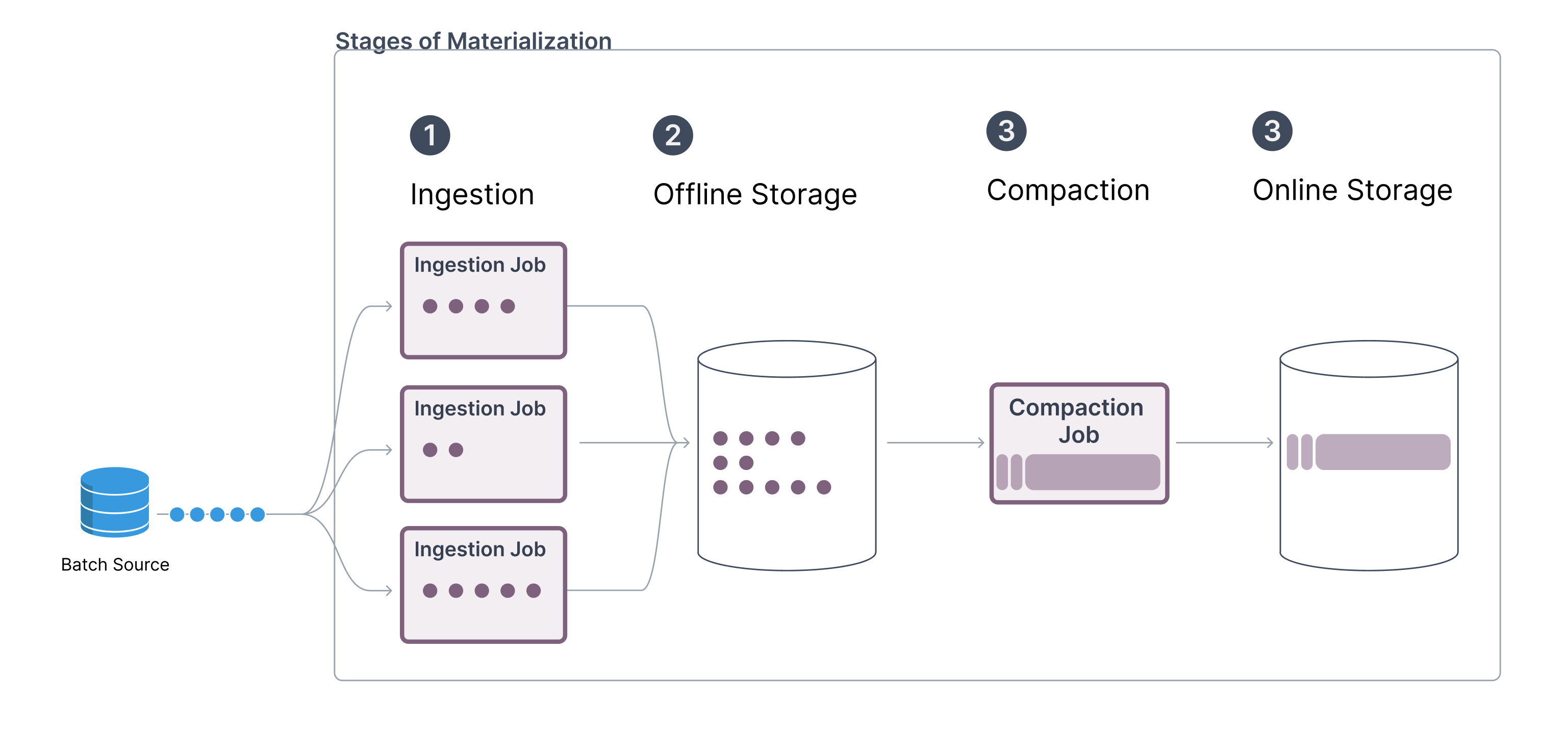 Batch
Materialization Stages
Batch
Materialization Stages
Stage 1: Incremental Materialization to the Offline Store
In the first stage, Tecton incrementally ingests, filters, and transforms data from raw data sources to the offline store. This typically means a daily job that ingests and transforms event data that has arrived in the customer’s raw data sources in the past 24 hours.
Data is stored transformed but unaggregated in the offline store. The data is transformed and filtered at this stage to minimize the computing needed for downstream jobs, like training data generation or the online compaction job. Data in the offline store is not tiled because for training data generation, Tecton will need to perform point-in-time correct joins to a given event.
Stage 2: Compaction and Healing for the Online Store
The second stage compacts and loads to the online store. After all jobs from stage 1 have finished, Tecton triggers a “compaction job” that will read data from the offline store, compact it into the tiles discussed above, and load them to the online store. Tecton uses DynamoDB’s S3 Bulk Import to make the online store load very cost-efficient.
Offline Retrieval (Training Data Generation)
To ensure efficient offline retrieval (e.g. for training data generation) Tecton makes several optimizations in the offline store and query engines that take advantage of the specific and predictable access query pattern for this data. For example, the offline store is partitioned based on event time, regularly optimized to improve data layout, and can be pre-aggregated at retrieval time completely in parallel. Tecton’s training data APIs efficiently generate point-in-time correct feature values, ensuring there is no training-serving skew.