How To Guide: Connect Rift Streaming to Kafka with Confluent
Create a simple Stream Feature View with Rift that processes events from a Confluent Kafka Topic.
Introduction
This guide assumes some basic familiarity with Tecton, including how to create and apply Features. If you are new to Tecton, we recommend first checking out our Tutorials which cover a range of topics designed to bring you up to speed working with Tecton.
While following this guide, you will:
- Create a Tecton
StreamSourcewith a PushConfig - Create a
StreamFeatureViewthat counts events on the StreamSource - Create an AWS Lambda Connector in Confluent
- Create a simple AWS Lambda function that is triggered by the Confluent connector. It acts as the binding connector that receives events from Confluent and pushes them to Tecton

Prerequisites
- A production Tecton workspace (this guide will not work with a lab workspace)
- An AWS account
- A Confluent Cloud account (sign up at https://confluent.cloud/ if you do not
have one)
- An up-and-running Confluent cluster with a topic in your Confluent account
- Schema Registry credentials
- Cluster credentials
Step 1: Create a Minimal StreamSource and StreamFeatureView
Once you have logged in to your live Tecton workspace, you can apply the following feature repository. It creates a StreamSource and StreamFeatureView.
Note that you bootstrap the StreamSource's batch data source with mocked events. In a production setting, you would point Tecton at a data warehouse table or data lake table, which represents a historical log of events that will be used for backfill operations.
from tecton import (
StreamSource,
FeatureService,
pandas_batch_config,
StreamFeatureView,
)
from datetime import timedelta
from tecton import PushConfig, StreamSource
from tecton.types import String, Int64, Timestamp, Field
from tecton import Aggregate, Entity
from tecton.types import Field, Int32
from datetime import datetime, timedelta
# Create a mock batch data source
@pandas_batch_config()
def mock_batch_source():
import pandas as pd
# Mock data
events = [
("click", 1, "2024-11-02 12:49:00"),
("purchase", 2, "2024-11-02 12:49:00"),
("view", 3, "2024-11-02 12:49:00"),
]
cols = ["event_type", "user_id", "timestamp_str"]
df = pd.DataFrame(events, columns=cols)
df["timestamp"] = pd.to_datetime(df["timestamp_str"])
return df
# Create a minimal Stream Source
push_stream_source = StreamSource(
name="push_stream_source",
schema=[
Field(name="event_type", dtype=String),
Field(name="user_id", dtype=Int64),
Field(name="timestamp", dtype=Timestamp),
],
stream_config=PushConfig(),
batch_config=mock_batch_source,
)
user = Entity(name="user_entity", join_keys=[Field("user_id", Int32)])
# Create a minimal SFV that counts the number of events on the stream source
demo_sfv = StreamFeatureView(
name="demo_sfv",
source=push_stream_source.unfiltered(),
entities=[user],
mode="pandas",
batch_schedule=timedelta(days=1),
timestamp_field="timestamp",
features=[
Aggregate(input_column=Field("event_type", String), function="count", time_window=timedelta(minutes=1)),
Aggregate(input_column=Field("event_type", String), function="count", time_window=timedelta(minutes=2)),
Aggregate(input_column=Field("event_type", String), function="count", time_window=timedelta(minutes=3)),
],
online=True,
offline=True,
feature_start_time=datetime(2024, 5, 1),
)
demo_fs = FeatureService(
name="demo_fs",
features=[demo_sfv],
)
Step 2: Create an AWS Lambda Function that will Receive Events from Confluent
Step 2a - Create Lambda
Head to the Lambda page in your AWS Console and create a new Lambda function.
Let's call it kafka-to-tecton
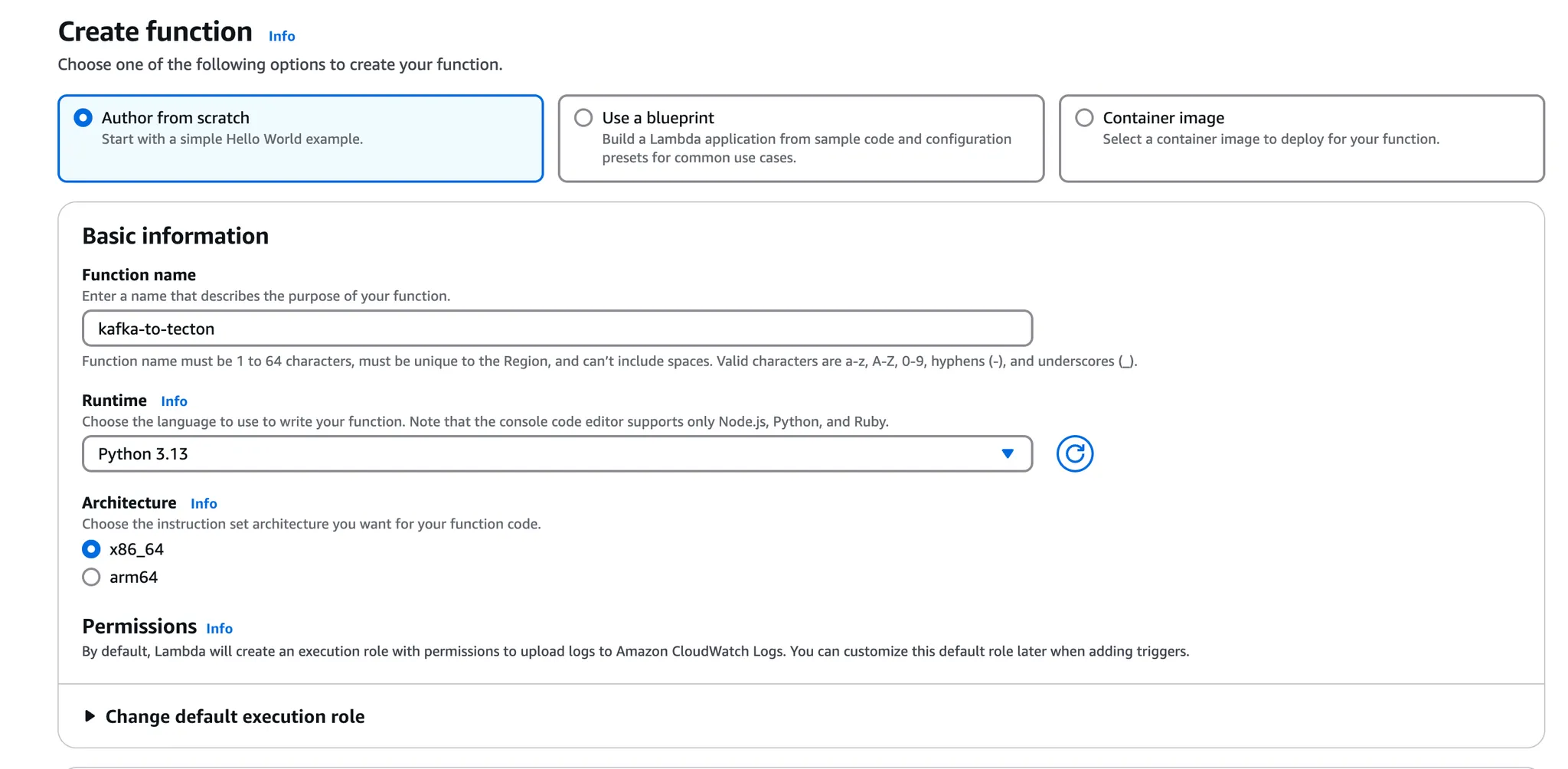
Make sure to change the Runtime to Python 3.13 and then create the function.
Step 2b - Configure Lambda to Push Events to Tecton
You can use the following code for your lambda handler to forward events to Tecton. Adjust the CONSTANTTs at the top of the script to make it work for your StreamSource. In a production setting, you likely would not want to hardcode those variables but inject them via Lambda environment variables.
import json
import pprint
import base64
import urllib3
# Constants
CLUSTER_NAME = "[Your-Cluster]"
API_KEY = "[Your-Service-Account-API-Key]"
WORKSPACE_NAME = "[Your-Workspace]"
STREAM_SOURCE = "[Your-Stream-Source]" # Name must match the StreamSource you created earlier
DRY_RUN = False
http = urllib3.PoolManager()
def send_events_to_tecton(events):
"""
Send a POST request to Tecton's ingest endpoint to submit feature data records.
Args:
events (list): List of events to be sent to Tecton.
Returns:
dict: Response from the Tecton ingest API.
"""
records = {STREAM_SOURCE: []}
for e in events:
records[STREAM_SOURCE].append(e)
url = f"https://preview.{CLUSTER_NAME}.tecton.ai/v2/ingest"
headers = {"Authorization": f"Tecton-key {API_KEY}", "Content-Type": "application/json"}
payload = json.dumps({"workspaceName": WORKSPACE_NAME, "dryRun": DRY_RUN, "records": records})
response = http.request("POST", url, body=payload, headers=headers)
# Check if the request was successful
if response.status == 200:
result = json.loads(response.data.decode("utf-8"))
pprint.pprint(result)
return result
else:
pprint.pprint(payload)
print(response.data.decode("utf-8"))
raise Exception(f"Request failed with status: {response.status}")
def extract_events_from_confluent_triggered_event(event):
"""
Extracts the "value" field from each payload in the event data.
Args:
event (list): List of dictionaries containing Kafka event data.
Returns:
list: A list of extracted "value" fields.
Raises:
ValueError: If the schema of the input data is not as expected.
"""
if not isinstance(event, list):
print(event)
raise ValueError("Event must be a list.")
values = []
for item in event:
if not isinstance(item, dict):
print(event)
raise ValueError(f"Each item in the event list must be a dictionary. Found: {type(item)}")
payload = item.get("payload")
if not isinstance(payload, dict):
print(event)
raise ValueError("Each item must have a 'payload' key containing a dictionary.")
# Ensure "value" exists and is a string
value = payload.get("value")
if not isinstance(value, dict):
print(event)
raise ValueError("'value' must be a dict.")
# Append the value
values.append(value)
return values
def lambda_handler(event, context):
extracted_events = extract_events_from_confluent_triggered_event(event)
result = send_events_to_tecton(extracted_events)
# Return a success status
return {"statusCode": 200, "body": json.dumps("Processed Confluent Kafka records")}
Deploy your Lambda function.
Step 2c - Create AWS Credentials that Confluent will use
In the same AWS account you created the Lambda function, create an IAM user with the following inline policy:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": ["lambda:InvokeFunction", "lambda:GetFunction"],
"Resource": "*"
}
]
}
Optional: To further restrict the permission, replace "*" with the ARN of your lambda function.
Next, create AWS credentials in the IAM console for the user you created. We will share those with Confluent in the following step.
Step 3 - Connect Confluent to your Lambda
In Confluent Cloud, create a new AWS Lambda Sink connector. Make sure your cluster was created on AWS:
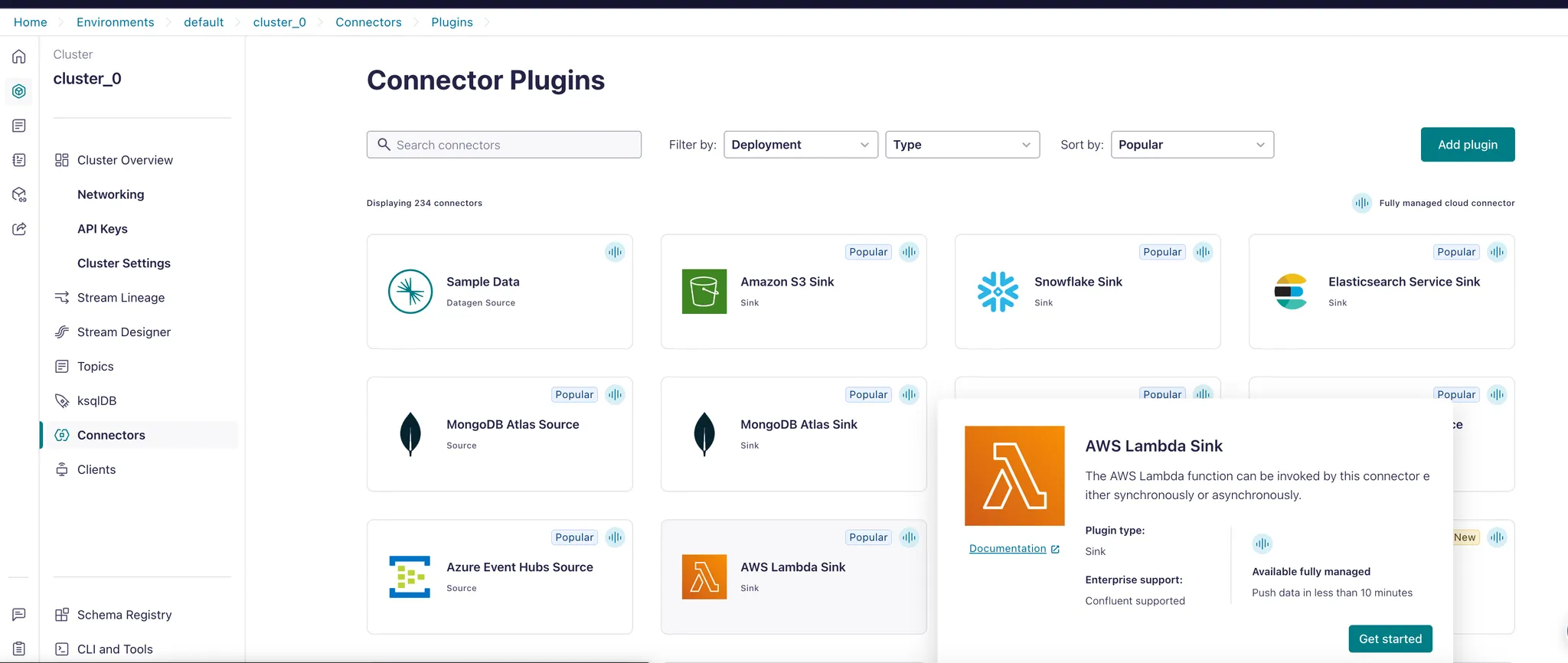
Configure it to read from your Confluent topic.
Then configure it to invoke your AWS Account’s Lambda function:
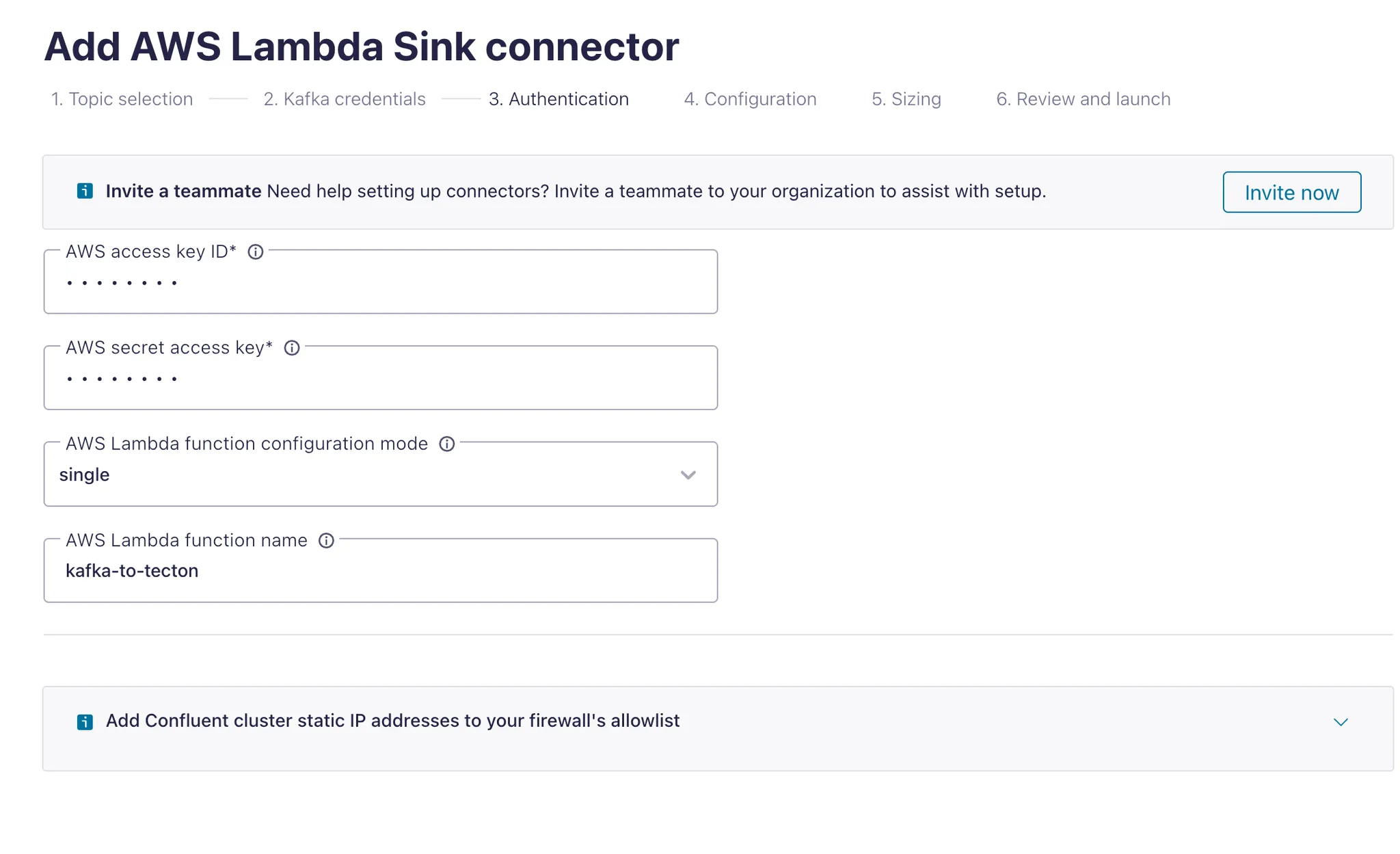
The AWS credentials are the ones you created earlier.
Select JSON_SR as the Kafka record value format:
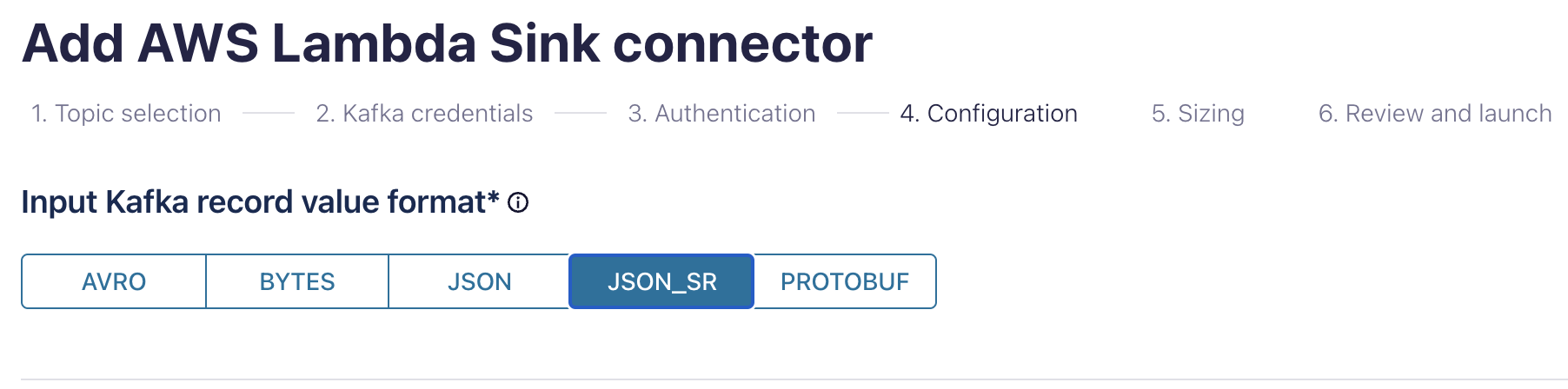
This step instructs the connector to use the Confluent Schema Registry and forward events as proper JSON dictionaries to the Lambda function.
Launch your connector!
Step 4 - Test the System End to End
To test that everything works as expected, let's ingest a few events into your Kafka topic and query Tecton for the results.
4a - Ingest events into your Kafka topic
You can use the following script and execute it locally to inject a few sample
events into your topic. Please note that the JSON schema definition matches the
schema of the push_stream_source we configured in Tecton earlier.
Make sure you replace the name of the topic and all the credentials:
CONFLUENT_KEY = "YOUR_KEY"
CONFLUENT_SECRET = "YOUR_SECRET"
BOOTSTRAP_SERVERS = "YOUR-SERVER"
SR_KEY = "YOUR_SR_KEY"
SR_SECRET = "YOUR_SR_SECRET"
SCHEMA_REGISTRY_URL = "YOUR_SR_REGISTRY_URL"
TOPIC_NAME = "YOUR_TOPIC"
import datetime
from confluent_kafka import SerializingProducer
from confluent_kafka.schema_registry import SchemaRegistryClient
from confluent_kafka.schema_registry.json_schema import JSONSerializer
# Confluent
schema_registry_config = {"url": SCHEMA_REGISTRY_URL, "basic.auth.user.info": f"{SR_KEY}:{SR_SECRET}"} # Add this line
# Configuration for Kafka producer
conf = {
"bootstrap.servers": BOOTSTRAP_SERVERS,
"security.protocol": "SASL_SSL",
"sasl.mechanism": "PLAIN",
"sasl.username": CONFLUENT_KEY,
"sasl.password": CONFLUENT_SECRET,
"session.timeout.ms": 45000,
"client.id": "ccloud-python-client-98a07c41-e7f3-4b18-b21a-f69e8a60c330",
"key.serializer": None,
"value.serializer": None,
}
schema_str = """
{
"$schema": "http://json-schema.org/draft-07/schema#",
"title": "TectonEvent",
"additionalProperties": false,
"properties": {
"record": {
"additionalProperties": false,
"properties": {
"event_type": {
"description": "The type of event being recorded.",
"type": "string"
},
"timestamp": {
"description": "An ISO 8601 formatted timestamp.",
"format": "date-time",
"type": "string"
},
"user_id": {
"description": "A string containing numeric characters only.",
"pattern": "^[0-9]+$",
"type": "string"
}
},
"required": [
"timestamp",
"user_id",
"event_type"
],
"type": "object"
}
},
"required": [
"record"
],
"type": "object"
}
"""
# Initialize Schema Registry Client
schema_registry_client = SchemaRegistryClient(schema_registry_config)
# Define the JSON serializer using the provided schema
json_serializer = JSONSerializer(schema_str, schema_registry_client)
# Add the serializer to Kafka producer configuration
conf["value.serializer"] = json_serializer
# Create a producer instance
producer = SerializingProducer(conf)
# Callback function to handle message delivery reports
def delivery_report(err, msg):
if err:
print(f"Message delivery failed: {err}")
else:
print(f"Message delivered to {msg.topic()} [{msg.partition()}]")
# Create a sample event to send
sample_event = {"record": {"timestamp": datetime.datetime.now().isoformat(), "user_id": "123", "event_type": "my_test"}}
# Produce the event to the specified topic
producer.produce(
TOPIC_NAME, key="event_key", value=sample_event, on_delivery=delivery_report # json.dumps(sample_event),
)
# Wait for all messages to be delivered
producer.flush()
Execute the script
4b - Query Tecton's Feature Service after You Have Injected New Events
Here's a sample Python script you can execute to query the FeatureService we created earlier.
Make sure you adjust the url, workspace name, and api_key.
Also make sure you pip install tecton-client
from tecton_client import TectonClient
import pprint
url = "https://[your_cluster].tecton.ai/"
workspace = "[your-workspace]"
api_key = "[your-api-key]"
fs_name = "demo_fs"
join_key_map = {"user_id": "123"}
client = TectonClient(url=url, default_workspace_name=workspace, api_key=api_key)
resp = client.get_features(feature_service_name=fs_name, join_key_map=join_key_map)
pprint.pprint(resp.get_features_dict())
Run the command and you should see output like this:
{'demo_sfv.event_type_count_1m_continuous': 1,
'demo_sfv.event_type_count_2m_continuous': 1,
'demo_sfv.event_type_count_3m_continuous': 1}
Et voila - you've created an end to end system that continuously streams events from Kafka into a StreamSource in Tecton. You can now create as many Streaming Feature Views as you would like off the same Kafka stream!