Define Features
In Tecton, a feature represents a single, measurable attribute derived from raw data, akin to a column in a dataset, or more simply, a transform applied to data. For instance, in a fraud detection system, a feature might be the average transaction amount for a user over the past 30 days. Features can be as simple as a column in a data source; however, some features may require calculation (aggregation, etc.) or more complex processing or transformation.
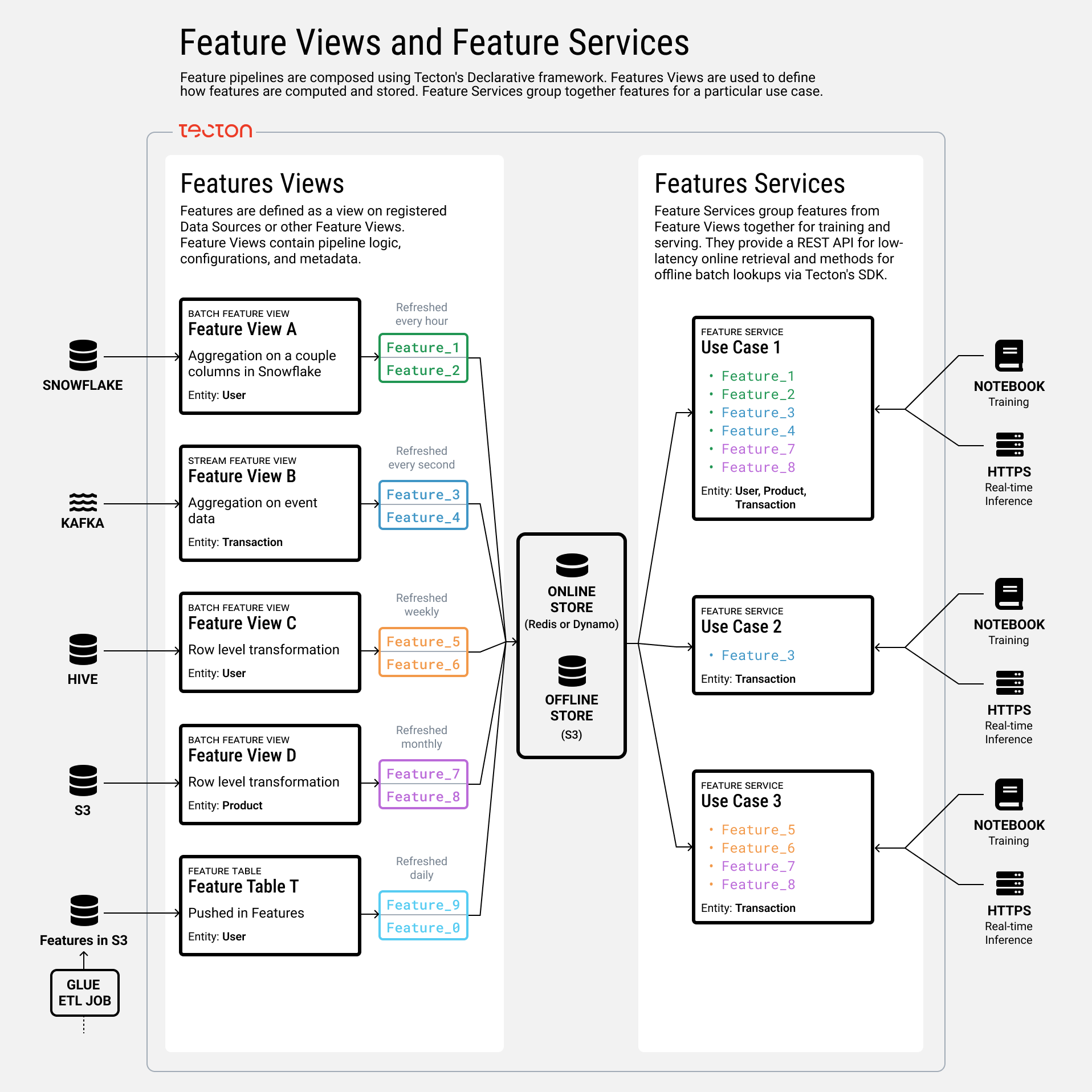
Features are defined within Feature Views, which are collections of related features computed from one or more data sources. Each Feature View includes the transformation logic, associated entities (such as the user for which you want the average transaction amount), and other configuration details for materialization and serving.
To serve these features to models during training and inference, Tecton utilizes Feature Services. A Feature Service groups together features from one or multiple Feature Views, providing a unified interface for models or rules engines to access the required features. This setup ensures consistency between training and serving environments and simplifies the process of feature retrieval.
Tecton's declarative framework streamlines the feature engineering process by allowing users to define complex transformations using built-in functions. For example, instead of manually coding the logic to compute the average transaction amount over a specific time window, you can leverage Tecton's built-in aggregation functions. This approach not only reduces development time but also ensures that features are computed efficiently and consistently across different environments.
Defining features involves specifying how raw data is transformed into machine learning (ML) features that are ready for both training and real-time inference.
Key Components in Tecton's Feature Definition Framework
-
Data Sources: These define connections to various data inputs—batch, stream, push, or request data sources—that serve as the foundation for feature computation.
-
Feature Views: Feature Views take in data sources as inputs, or in some cases other Feature Views, and define transformations to compute one or more features. They also provide Tecton with metadata and configurations for orchestration, serving, and monitoring. There are three types of Feature Views:
- Batch Feature Views: Process offline data from batch sources like data lakes or warehouses at scheduled intervals, publishing features to the online and/or offline stores.
- Stream Feature Views: Handle data from stream sources (e.g., Kafka, Kinesis) in near-real-time, publishing features to the online store. They can also backfill using historical logs.
- Realtime Feature Views: Compute features at request time from real-time sources or other Feature Views, enabling on-the-fly feature computation when pre-computation isn't feasible.
-
Entities: The primary key of your feature. In other words, the thing or trigger that your feature is built around. For example, in Transaction Fraud an entity might be a transaction or a user.
-
Feature Services: Group features from multiple Feature Views to serve them together for training and inference. They provide endpoints for fetching training data via the Tecton SDK or real-time feature vectors through Tecton's HTTP API and serving it to consumers such as models or rules engines.
By connecting Data Sources to Feature Views and then to Feature Services, Tecton orchestrates the end-to-end process of feature engineering, from data ingestion to serving features in production.
What's Next
Defining Features is the first step in the overall production process. Begin by creating Feature Views.