Embedding Engine
Embeddings—condensed, rich representations of unstructured data—have become foundational in the evolution of Predictive and Generative AI. By capturing the essential features of complex data, embeddings enable AI models to perform tasks such as classification, clustering, and recommendation with remarkable accuracy and efficiency.
Tecton’s Embedding Engine is a robust, distributed framework designed to meet the growing demands of modern AI applications. With its high-performance architecture and flexible design, the Embedding Engine empowers users to compute, manage, and seamlessly integrate embeddings into their AI workflows. Whether you’re building recommendation systems, natural language processing models, or other AI-driven solutions, Tecton’s Embedding Engine provides the tools and scalability needed to bring your applications to production grade.
Architecture Overview
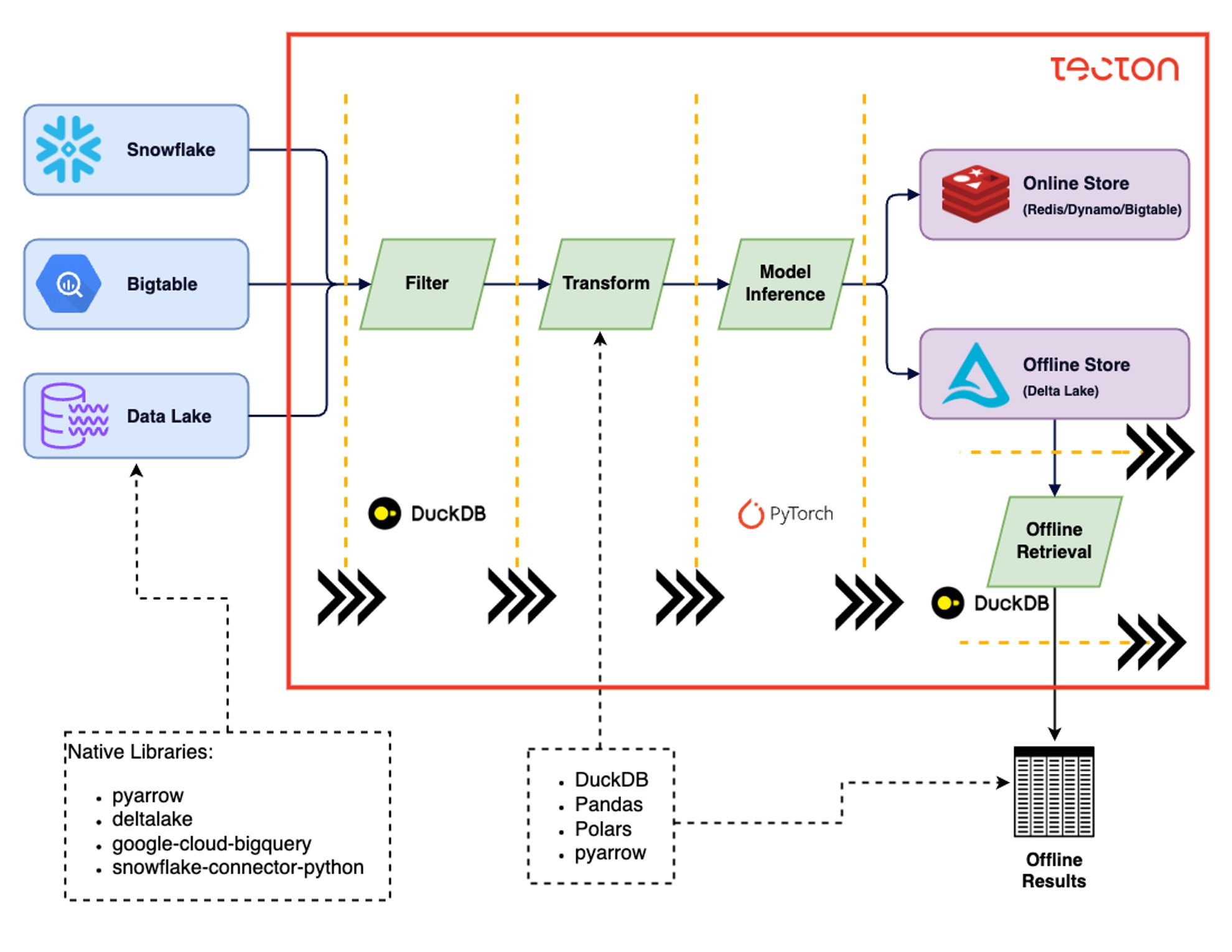
Challenges of using Embeddings in Production
There are major challenges faced by modelers working with embeddings at scale for building production AI applications. These challenges include:
- Compute Resource Management: Balancing computational costs and performance for large-scale embedding generation
- Data Pipeline Orchestration: Managing complex data flows from various sources through embedding models to AI pipelines
- Model Integration Complexity: Difficulty in seamlessly incorporating and switching between open-source and custom embedding models
- Training Data Generation: Efficiently creating accurate, large-scale training data for model retraining
- Experimentation and Reproducibility: Optimizing embedding approaches while ensuring consistency between testing and production
- Efficient Storage and Retrieval: Designing specialized architectures for storing and quickly accessing millions of embeddings
- Scalability: Handling unpredictable traffic patterns without performance degradation or resource waste
- Operational Challenges: Addressing collaboration, version control, governance, and safety standards in embedding pipeline
Benefits of the Embedding Engine
Tecton’s Embedding Engine solves the aforementioned challenges through:
Performance Optimizations
- Dynamic Token Batching: Automatically adjusts batch size in real-time to maximize throughput, considering sequence lengths, model architecture, and hardware.
- Automated Token Budget Selection: Utilizes CUDA memory metrics to estimate GPU memory requirements per token, optimizing GPU usage.
- Cuda OOM Batch Splitting: Automatically splits batches during inference to prevent out-of-memory (OOM) errors.
- Optimized Storage & Retrieval: Combines vector databases with Tecton’s serving cache for fast, efficient embedding storage and retrieval.
Simplicity & Flexibility
- Simple UX: Defining online/offline-consistent, highly-performant embedding features with only a few lines of code.
- Open Source Model & Custom Model: Users can effortlessly select a Tecton-managed open-source model with a single line of code or bring their own models, offering unparalleled flexibility.
- Ease of Experimentation & Reproducibility: Local development enable users to fastly experiment different embedding models. Tecton’s “features-as-code” paradigm ensures reproducibility of embeddings and guarantees online-offline consistency.
Production-Ready Scalability
- Online Autoscaling: Effortlessly scales resources to handle spikes and seasonal increases in embedding lookup volume, ensuring cost-efficiency with Feature Server Autoscaling
- Distributed inference: Scales inference workloads across multiple GPUs and concurrent jobs to handle large-scale tasks.
- Larger-than-memory datasets: Powered by Rift, built on Arrow and DuckDB, enabling seamless processing of datasets larger than memory by spilling to disk.