📚 Tecton Quickstart Tutorial
Tecton helps you build and productionize real-time ML models by making it easy to define, test, and deploy features for training and serving.
Let’s see how quickly we can build a real-time fraud detection model and bring it online.
In this tutorial we will:
- Connect to data on S3
- Define and test features
- Generate a training dataset and train a model
- Productionize our features for real-time serving
- Run real-time inference to predict fraudulent transactions
This tutorial is expected to take about 30 minutes (record time for building a real-time ML application 😎).
Most of this tutorial is intended to be run in a notebook with access to Spark and the Tecton SDK installed. See these instructions to setup notebooks for Databricks or EMR.
Some steps will explicitly note to run commands in your terminal.
Be sure to install the Tecton SDK before getting started. You will also need to install the following packages, used for reading data from S3 and to be able to train a model later in this tutorial:
pip install s3fs fsspec scikit-learn
Before you start, run tecton login [my-account].tecton.ai in your CLI. Be sure
to fill in your organization's Tecton account name.
🔎 Examine raw data
First let's examine some historical transaction data that we have available on S3.
import pandas as pd
df = pd.read_parquet("s3://tecton.ai.public/tutorials/fraud_demo/transactions/data.pq", storage_options={"anon": True})
display(df.head(5))
| user_id | transaction_id | category | amt | is_fraud | merchant | merch_lat | merch_long | timestamp | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | user_884240387242 | 3eb88afb219c9a10f5130d0b89a13451 | gas_transport | 68.23 | 0 | fraud_Kutch, Hermiston and Farrell | 42.71 | -78.3386 | 2023-06-20 10:26:41 |
| 1 | user_268514844966 | 72e23b9193f97c2ba654854a66890432 | misc_pos | 32.98 | 0 | fraud_Lehner, Reichert and Mills | 39.1536 | -122.364 | 2023-06-20 12:57:20 |
| 2 | user_722584453020 | db7a41ce2d16a4452c973418d9e544b1 | home | 4.5 | 0 | fraud_Koss, Hansen and Lueilwitz | 33.0332 | -105.746 | 2023-06-20 14:49:59 |
| 3 | user_337750317412 | edfc42f7bc4b86d8c142acefb88c4565 | misc_pos | 7.68 | 0 | fraud_Buckridge PLC | 40.6828 | -88.8084 | 2023-06-20 14:50:13 |
| 4 | user_934384811883 | 93d28b6d2e5afebf9c40304aa709ab29 | kids_pets | 68.97 | 1 | fraud_Lubowitz-Walter | 39.1443 | -96.125 | 2023-06-20 15:55:09 |
👩💻 Define and test features locally
In our data, we see that there's information on users' transactions over time.
Let's use this data to create the following features:
- A user's average transaction amount over 1, 3, and 7 days.
- A user's total transaction count over 1, 3, and 7 days.
To build these features, we will define a "Batch Source" and "Batch Feature View" using Tecton's Feature Engineering Framework.
A Feature View is how we define our feature logic and give Tecton the information it needs to productionize, monitor, and manage features.
Tecton's development workflow allows you to build and test features, as well as generate training data entirely in a notebook! Let's try it out.
from tecton import Entity, BatchSource, FileConfig, batch_feature_view, Aggregation
from tecton.types import Field, String, Timestamp, Float64
from datetime import datetime, timedelta
transactions = BatchSource(
name="transactions",
batch_config=FileConfig(
uri="s3://anonymous@tecton.ai.public/tutorials/fraud_demo/transactions/data.pq",
file_format="parquet",
timestamp_field="timestamp",
),
)
# An entity defines the concept we are modeling features for
# The join keys will be used to aggregate, join, and retrieve features
user = Entity(name="user", join_keys=["user_id"])
# We use SQL to transform the raw data and Tecton aggregations to efficiently and accurately compute metrics across raw events
# Feature View decorators contain a wide range of parameters for materializing, cataloging, and monitoring features
@batch_feature_view(
description="User transaction metrics over 1, 3 and 7 days",
sources=[transactions],
entities=[user],
mode="pyspark",
aggregation_interval=timedelta(days=1),
aggregations=[
Aggregation(function="mean", column="amt", time_window=timedelta(days=1)),
Aggregation(function="mean", column="amt", time_window=timedelta(days=3)),
Aggregation(function="mean", column="amt", time_window=timedelta(days=7)),
Aggregation(function="count", column="amt", time_window=timedelta(days=1), name="transaction_count_1d_1d"),
Aggregation(function="count", column="amt", time_window=timedelta(days=3), name="transaction_count_3d_1d"),
Aggregation(function="count", column="amt", time_window=timedelta(days=7), name="transaction_count_7d_1d"),
],
schema=[Field("user_id", String), Field("timestamp", Timestamp), Field("amt", Float64)],
)
def user_transaction_metrics(transactions):
return transactions[["user_id", "timestamp", "amt"]]
# After we define local objects, we use `.validate()` to check the correctness of the definition
# and make it ready to query
user_transaction_metrics.validate()
BatchFeatureView 'user_transaction_metrics': Validating 3 dependencies.
BatchSource 'transactions': Deriving schema.
BatchSource 'transactions': Successfully validated.
Entity 'user': Successfully validated.
Transformation 'user_transaction_metrics': Successfully validated.
BatchFeatureView 'user_transaction_metrics': Successfully validated.
🧪 Test features interactively
Now that we've defined and validated our Feature View, we can use
get_historical_features to produce a range of feature values and check out the
data.
start = datetime(2022, 1, 1)
end = datetime(2022, 2, 1)
df = user_transaction_metrics.get_historical_features(start_time=start, end_time=end).to_pandas()
display(df.head(5))
| user_id | amt_mean_1d_1d | amt_mean_3d_1d | amt_mean_7d_1d | transaction_count_1d_1d | transaction_count_3d_1d | transaction_count_7d_1d | timestamp | _effective_timestamp | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | user_131340471060 | 21.07 | 93.395 | 49.2267 | 1 | 2 | 6 | 2022-01-01 00:00:00 | 2022-01-01 00:00:00 |
| 1 | user_131340471060 | 144.45 | 110.413 | 71.258 | 1 | 3 | 5 | 2022-01-02 00:00:00 | 2022-01-02 00:00:00 |
| 2 | user_131340471060 | 4.14 | 56.5533 | 69.26 | 1 | 3 | 5 | 2022-01-03 00:00:00 | 2022-01-03 00:00:00 |
| 3 | user_131340471060 | 15.1 | 54.5633 | 60.2333 | 1 | 3 | 6 | 2022-01-04 00:00:00 | 2022-01-04 00:00:00 |
| 4 | user_131340471060 | 91.34 | 91.34 | 55.22 | 1 | 1 | 5 | 2022-01-07 00:00:00 | 2022-01-07 00:00:00 |
🧮 Generate training data
We'll build our training dataset from labeled historical transactions and try to predict the "is_fraud" column for a given transaction.
Let's load up some training events.
training_events = pd.read_parquet(
"s3://tecton.ai.public/tutorials/fraud_demo/transactions/data.pq", storage_options={"anon": True}
)[["user_id", "timestamp", "amt", "is_fraud"]].head(1000)
display(training_events.head(5))
| user_id | timestamp | amt | is_fraud | |
|---|---|---|---|---|
| 0 | user_884240387242 | 2023-06-20 10:26:41 | 68.23 | 0 |
| 1 | user_268514844966 | 2023-06-20 12:57:20 | 32.98 | 0 |
| 2 | user_722584453020 | 2023-06-20 14:49:59 | 4.5 | 0 |
| 3 | user_337750317412 | 2023-06-20 14:50:13 | 7.68 | 0 |
| 4 | user_934384811883 | 2023-06-20 15:55:09 | 68.97 | 1 |
Next, let's ask Tecton to join the feature we just created into our labeled events. Tecton will perform a time travel join to fetch the point-in-time correct feature values.
To do this we will create a "Feature Service" which defines the list of features that will be used by our model.
We can call get_historical_features(training_events) on the Feature Service to
get historically accurate features for each event.
from tecton import FeatureService
fraud_detection_feature_service = FeatureService(
name="fraud_detection_feature_service", features=[user_transaction_metrics]
)
fraud_detection_feature_service.validate()
training_data = fraud_detection_feature_service.get_historical_features(training_events).to_pandas().fillna(0)
display(training_data.head(5))
FeatureService 'fraud_detection_feature_service': Successfully validated.
| user_id | timestamp | amt | is_fraud | user_transaction_metrics__amt_mean_1d_1d | user_transaction_metrics__amt_mean_3d_1d | user_transaction_metrics__amt_mean_7d_1d | user_transaction_metrics__transaction_count_1d_1d | user_transaction_metrics__transaction_count_3d_1d | user_transaction_metrics__transaction_count_7d_1d | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | user_131340471060 | 2023-06-21 13:57:50 | 73.8 | 0 | 96.85 | 103.373 | 103.373 | 1 | 3 | 3 |
| 1 | user_131340471060 | 2023-06-27 00:52:08 | 46.48 | 0 | 0 | 0 | 85.325 | 0 | 0 | 2 |
| 2 | user_131340471060 | 2023-07-05 10:42:35 | 157.82 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | user_131340471060 | 2023-07-11 02:06:55 | 3.53 | 0 | 0 | 0 | 157.82 | 0 | 0 | 1 |
| 4 | user_131340471060 | 2023-07-16 01:04:41 | 6.42 | 1 | 0 | 0 | 3.53 | 0 | 0 | 1 |
🧠 Train a model
Once we have our training data set from Tecton, we can use whatever framework we want for training the model.
In the example below, we'll train a simple Logistic Regression model using sklearn!
from sklearn.pipeline import make_pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OneHotEncoder, StandardScaler
from sklearn.compose import ColumnTransformer
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn import metrics
df = training_data.drop(["user_id", "timestamp", "amt"], axis=1)
X = df.drop("is_fraud", axis=1)
y = df["is_fraud"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
num_cols = X_train.select_dtypes(exclude=["object"]).columns.tolist()
cat_cols = X_train.select_dtypes(include=["object"]).columns.tolist()
num_pipe = make_pipeline(SimpleImputer(strategy="median"), StandardScaler())
cat_pipe = make_pipeline(
SimpleImputer(strategy="constant", fill_value="N/A"), OneHotEncoder(handle_unknown="ignore", sparse=False)
)
full_pipe = ColumnTransformer([("num", num_pipe, num_cols), ("cat", cat_pipe, cat_cols)])
model = make_pipeline(full_pipe, LogisticRegression(max_iter=1000, random_state=42))
model.fit(X_train, y_train)
y_predict = model.predict(X_test)
print(metrics.classification_report(y_test, y_predict, zero_division=0))
| precision | recall | f1-score | support | |
|---|---|---|---|---|
| 0 | 0.88 | 1.00 | 0.94 | 265 |
| 1 | 0.00 | 0.00 | 0.00 | 35 |
| accuracy | 0.88 | 300 | ||
| macro avg | 0.44 | 0.50 | 0.47 | 300 |
| weighted avg | 0.78 | 0.88 | 0.83 | 300 |
Of course, you can continue iterating on features and retraining your model until you are ready to productionize.
🚀 Apply your Tecton application to production
Tecton objects get registered via a declarative workflow. Features are defined as code in a repo and applied to a workspace in a Tecton account using the Tecton CLI. This approach enables productionisation best practices such as "features as code," CI/CD, and unit testing.
This section will require you to install the Tecton CLI via:
pip install tecton
We recommend that you first create a virtual environment for the installation.
Check out Installing the Tecton CLI for more information and installing the CLI.
1. Create a Tecton Feature Repository
Let's switch over from our notebook to a terminal and create a new Tecton Feature Repository. For now we will put all our definitions in a single file.
✅ Run these commands to create a new Tecton repo.
mkdir tecton-feature-repo
cd tecton-feature-repo
touch features.py
tecton init
2. Fill in features.py and enable materialization
✅ Now copy & paste the definition of the Tecton objects you created in your
notebook to features.py (copied below).
On our Feature View we've added four parameters to enable backfilling and ongoing materialization to the online and offline Feature Store:
online=Trueoffline=Truefeature_start_time=datetime(2023,1,1)batch_schedule=timedelta(days=1)
When we apply our changes to a Live Workspace, Tecton will automatically kick
off jobs to backfill feature data from feature_start_time. Frontfill jobs will
then run on the defined batch_schedule.
Besides the new materialization parameters, the code below is exactly the same as our definitions above. No changes are required when moving from interactive development to productionisation!
features.py
from tecton import Entity, BatchSource, FileConfig, batch_feature_view, Aggregation, FeatureService
from tecton.types import Field, String, Timestamp, Float64
from datetime import datetime, timedelta
transactions = BatchSource(
name="transactions",
batch_config=FileConfig(
uri="s3://anonymous@tecton.ai.public/tutorials/fraud_demo/transactions/data.pq",
file_format="parquet",
timestamp_field="timestamp",
),
)
# An entity defines the concept we are modeling features for
# The join keys will be used to aggregate, join, and retrieve features
user = Entity(name="user", join_keys=["user_id"])
# We use SQL to transform the raw data and Tecton aggregations to efficiently and accurately compute metrics across raw events
# Feature View decorators contain a wide range of parameters for materializing, cataloging, and monitoring features
@batch_feature_view(
description="User transaction metrics over 1, 3 and 7 days",
sources=[transactions],
entities=[user],
mode="pyspark",
aggregation_interval=timedelta(days=1),
aggregations=[
Aggregation(function="mean", column="amt", time_window=timedelta(days=1)),
Aggregation(function="mean", column="amt", time_window=timedelta(days=3)),
Aggregation(function="mean", column="amt", time_window=timedelta(days=7)),
Aggregation(function="count", column="amt", time_window=timedelta(days=1)),
Aggregation(function="count", column="amt", time_window=timedelta(days=3)),
Aggregation(function="count", column="amt", time_window=timedelta(days=7)),
],
schema=[Field("user_id", String), Field("timestamp", Timestamp), Field("amt", Float64)],
online=True,
offline=True,
feature_start_time=datetime(2023, 1, 1),
batch_schedule=timedelta(days=1),
)
def user_transaction_metrics(transactions):
return transactions[["user_id", "timestamp", "amt"]]
fraud_detection_feature_service = FeatureService(
name="fraud_detection_feature_service", features=[user_transaction_metrics]
)
3. Apply your changes to a new workspace
Our last step is to login to your organization's Tecton account and apply our repo to a workspace!
✅ Run the following commands in your terminal to create a workspace and apply your changes:
The tecton apply step will kick off jobs in your connected data platform and
incur some cost, however the size of the data being transformed and materialized
is relatively small (~700 records per month in the raw data).
tecton login [your-org-account-name].tecton.ai
tecton workspace create [your-name]-quickstart --live
tecton apply
Using workspace "[your-name]-quickstart" on cluster https://app.tecton.ai
✅ Imported 1 Python module from the feature repository
✅ Imported 1 Python module from the feature repository
⚠️ Running Tests: No tests found.
✅ Collecting local feature declarations
✅ Performing server-side feature validation: Initializing.
↓↓↓↓↓↓↓↓↓↓↓↓ Plan Start ↓↓↓↓↓↓↓↓↓↓
+ Create Batch Data Source
name: transactions
+ Create Entity
name: user
+ Create Transformation
name: user_transaction_metrics
description: Trailing average transaction amount over 1, 3 and 7 days
+ Create Batch Feature View
name: user_transaction_metrics
description: Trailing average transaction amount over 1, 3 and 7 days
materialization: 11 backfills, 1 recurring batch job
> backfill: 10 Backfill jobs 2021-12-25 00:00:00 UTC to 2023-08-16 00:00:00 UTC writing to the Offline Store
1 Backfill job 2023-08-16 00:00:00 UTC to 2023-08-23 00:00:00 UTC writing to both the Online and Offline Store
> incremental: 1 Recurring Batch job scheduled every 1 day writing to both the Online and Offline Store
+ Create Feature Service
name: fraud_detection_feature_service
↑↑↑↑↑↑↑↑↑↑↑↑ Plan End ↑↑↑↑↑↑↑↑↑↑↑↑
Generated plan ID is 8d01ad78e3194a5dbd3f934f04d71564
View your plan in the Web UI: https://app.tecton.ai/app/[your-name]-quickstart/plan-summary/8d01ad78e3194a5dbd3f934f04d71564
⚠️ Objects in plan contain warnings.
Note: Updates to Feature Services may take up to 60 seconds to be propagated to the real-time feature-serving endpoint.
Note: This workspace ([your-name]-quickstart) is a "Live" workspace. Applying this plan may result in new materialization jobs which will incur costs. Carefully examine the plan output before applying changes.
Are you sure you want to apply this plan to: "[your-name]-quickstart"? [y/N]> y
🎉 all done!
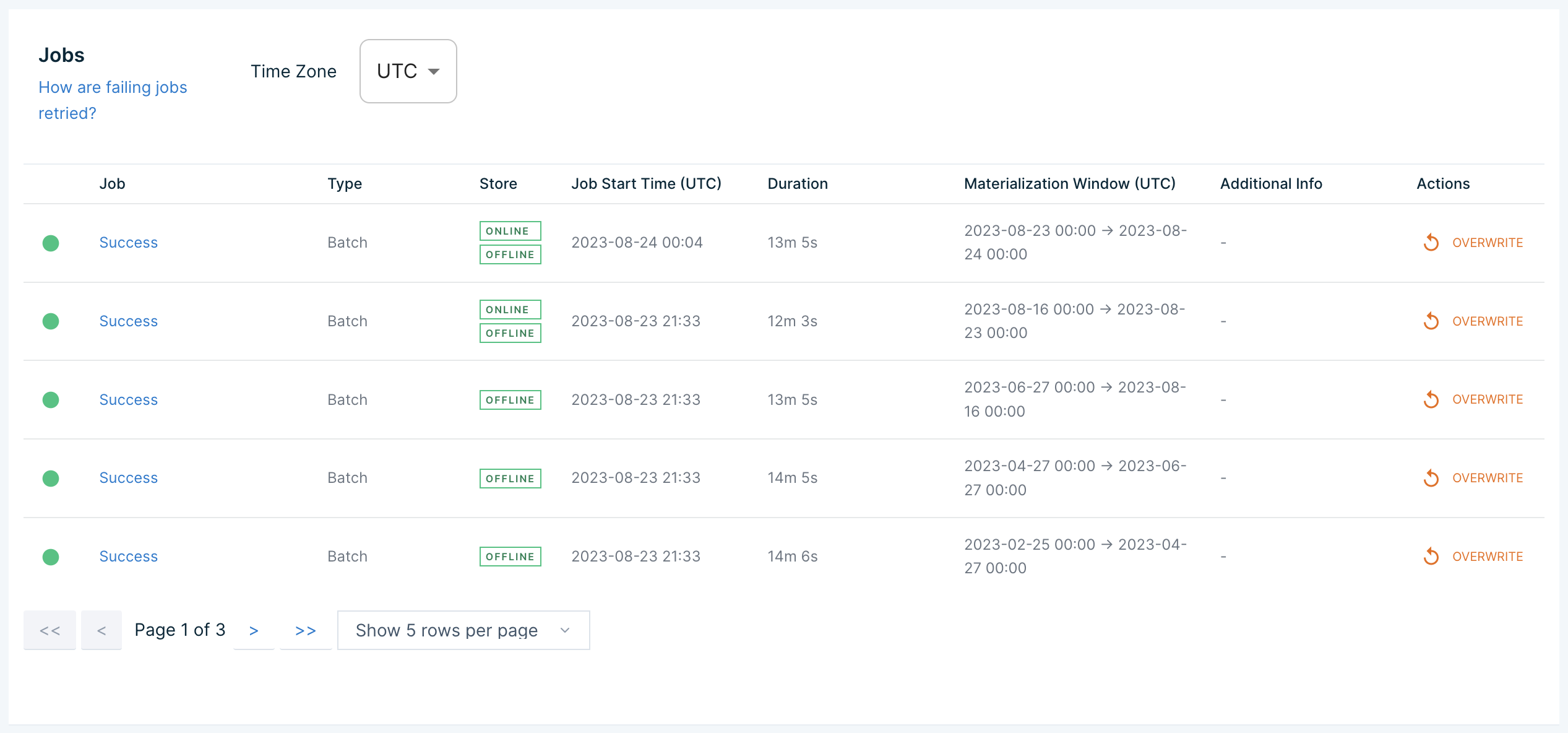
🟢 Check on backfilling status
Now that we've applied our features to a live workspace and enabled materialization to the online and offline store, we can check on the status of backfill jobs in the Tecton Web UI.
This can be found at:
https://[your-org-account-name].tecton.ai/app/repo/[your-workspace-name]/features/user_transaction_metrics/materialization
Once the backfill jobs have completed, we can fetch feature values online!
⚡️ Create a function to retrieve features from Tecton's REST API
Now let's use Tecton's REST API to retrieve features at low latency.
To do this, you will first need to create a new Service Account and give it access to read features from your workspace.
Follow these commands in your terminal:
tecton service-account create --name "[your-name]-quickstart" --description "Quickstart service account"
tecton access-control assign-role -r consumer -w [your-name]-quickstart -s [service account id from last command]
You will use the API key from the first command in the cell below where we define a function to retrieve online feature data for a given user.
import requests, json
def get_online_feature_data(user_id):
TECTON_API_KEY = "[your-api-key]"
WORKSPACE_NAME = "[your-workspace-name]"
ACCOUNT_NAME = "[your-org-account-name]"
headers = {"Authorization": "Tecton-key " + TECTON_API_KEY}
request_data = f"""{{
"params": {{
"feature_service_name": "fraud_detection_feature_service",
"join_key_map": {{"user_id": "{user_id}"}},
"metadata_options": {{"include_names": true}},
"workspace_name": "{WORKSPACE_NAME}"
}}
}}"""
online_feature_data = requests.request(
method="POST",
headers=headers,
url=f"https://{ACCOUNT_NAME}.tecton.ai/api/v1/feature-service/get-features",
data=request_data,
)
online_feature_data_json = json.loads(online_feature_data.text)
return online_feature_data_json
Now we can use our function to retrieve features at low latency!
user_id = "user_502567604689"
feature_data = get_online_feature_data(user_id)
if "result" not in feature_data:
print("Feature data is not materialized")
else:
print(feature_data["result"])
{'features': [None, 14.64, 12.296666666666667, None, '2', '3']}
💡 Create a function to make a prediction given feature data
Now that we can fetch feature data online, let's create a function that takes a feature vector and runs model inference to get a fraud prediction.
Typically you'd instead use a model serving API that is hosting your model. Here we run inference directly in our notebook for simplicity.
import pandas as pd
def get_prediction_from_model(feature_data):
columns = [f["name"].replace(".", "__") for f in feature_data["metadata"]["features"]]
data = [feature_data["result"]["features"]]
features = pd.DataFrame(data, columns=columns)
return model.predict(features)[0]
✨ Run inference using features from Tecton
Let's put it all together and run inference!
We can fetch our online features from Tecton, call our inference function, and get a prediction.
user_id = "user_502567604689"
online_feature_data = get_online_feature_data(user_id)
prediction = get_prediction_from_model(online_feature_data)
print(prediction)
0
🔥 Create a function to evaluate a user transaction and accept or reject it
Our final step is to use our new fraud prediction pipeline to make decisions and take action in our application.
In the function below we use simple business logic to decide whether to accept or reject a transaction based on our predicted fraud score.
def evaluate_transaction(user_id):
online_feature_data = get_online_feature_data(user_id)
is_predicted_fraud = get_prediction_from_model(online_feature_data)
if is_predicted_fraud == 0:
return "Transaction accepted."
else:
return "Transaction denied."
💰 Evaluate a transaction
Put it all together and we have a single online, low-latency decision API for our application. Try it out below!
evaluate_transaction("user_502567604689")
Transaction accepted.
⭐️ Conclusion
In this tutorial, we were able to quickly make an end to end real-time fraud detection application using features built in Tecton.
We tested our features, built training data sets, productionized features with engineering best practices, retrieved features online, and made decisions in real time!
But Tecton can do so much more:
- streaming features
- real-time features
- monitoring
- unit testing
- cataloging and discovery
- access controls
- cost management
- rules engines
...and more.
Next, we recommend checking out our tutorial on building streaming features to learn more about how to infuse your models with real-time data using nothing more than Python!