Serverless Feature Retrieval from any Python environment
This feature is currently in Public Preview.
- Your Athena workgroup must be configured to use Athena Engine 3.
- You cannot use the Athena connector to compute features with the `get_historical_features()` method’s `from_source` parameter set to `True`. Features can only be read from the offline store.
- Athena supported aggregations are sum, min, max, count, mean, stddev_samp, stddev_pop, var_samp, var_pop
Summary
When using the Tecton SDK with Databricks or EMR, the Tecton SDK leverages the existing Spark context to retrieve features from the offline store. As a result, the SDK methods for offline feature retrieval only work in Python environments that have access to an interactive Spark context (such as Databricks or AWS EMR notebooks).
As an alternative, users can use the Tecton SDK with Athena to access features from Tecton’s offline store in any Python environment that has access to AWS (e.g. your local laptop, a Jupyter notebook, Kubeflow pipelines etc.).
How the SDK works with Athena
The following diagram shows how Athena fits into Tecton’s Architecture:
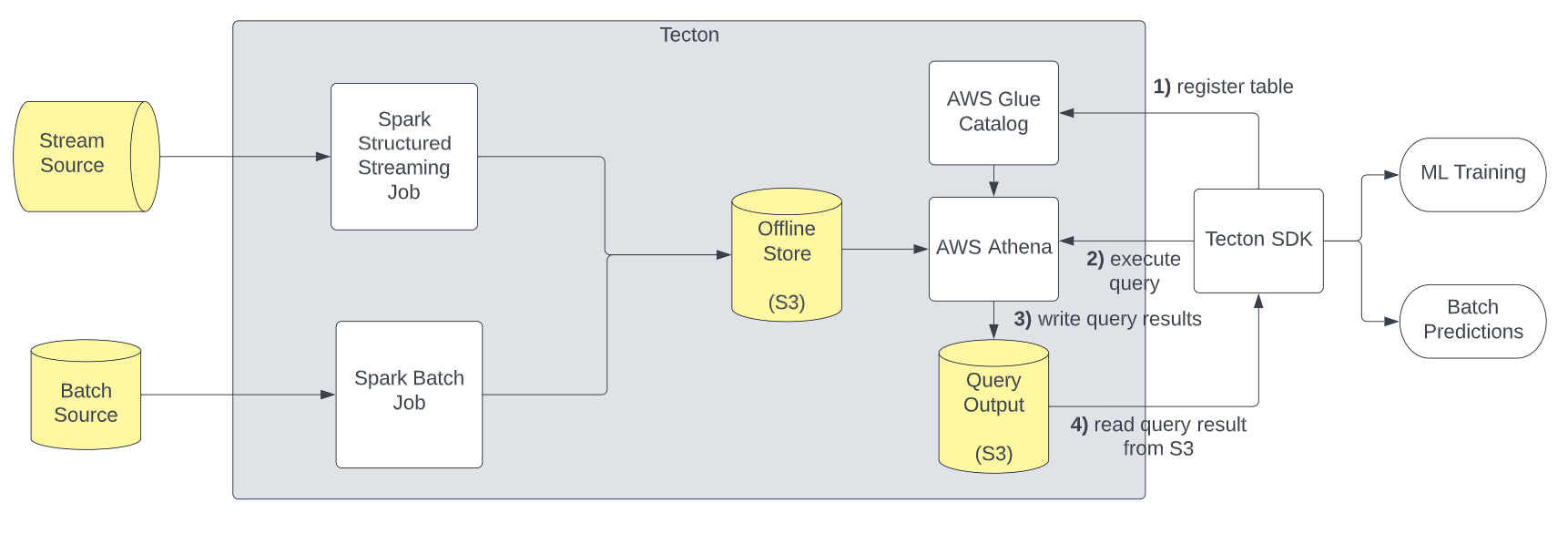
When you retrieve features from the offline store, the SDK executes the following steps:
- Tecton registers tables in AWS Glue for Feature Views and Feature Tables that the user attempts to read data from. Those tables point at the Feature View’s Offline Store location on S3.
- Tecton’s SDK builds and executes Athena SQL queries to fetch historical feature data from the S3-based Tecton Offline Store.
- Athena writes the query result to S3.
- Tecton’s SDK reads the result from S3 and returns a pandas DataFrame.
Additionally, if you retrieve features using a pandas DataFrame spine, Tecton will upload the spine to S3 and register an Athena table for it.
Supported Tecton SDK operations
Athena is used for the following SDK operations:
FeatureView.get_historical_features()FeatureTable.get_historical_features()FeatureService.get_historical_features()
Otherwise, the Tecton SDK uses a Spark context for other operations that read
data, such as DataSource.get_dataframe().
Installation
Your Athena workgroup must be configured to use Athena Engine 3.
To install the Athena connector in your notebook, run:
pip install 'tecton[athena]'
To enable the Athena connector, set TECTON_OFFLINE_RETRIEVAL_COMPUTE_MODE as
follows:
import tecton
tecton.conf.set("TECTON_OFFLINE_RETRIEVAL_COMPUTE_MODE", "athena")
Athena session configuration
The following configuration can be set on the Athena Session. All the configurations are optional, except for the workgroup which must be configured to use Athena Engine 3 and specified below:
import tecton_athena
session = tecton_athena.athena_session.get_session()
config = session.config
config.boto3_session = ... # Optional: Boto3 session
config.workgroup = ... # Required: Athena workgroup which must be configured to use Athena Engine 3.
config.encryption = ... # Optional: Valid values: [None, 'SSE_S3', 'SSE_KMS']. Notice: 'CSE_KMS' is not supported.
config.kms_key = ... # Optional: For SSE-KMS, this is the KMS key ARN or ID.
config.database = ... # Optional: Name of the Database in the Catalog
config.s3_path = ... # Optional: S3 Location where spines will be uploaded and Athena output will be stored
config.spine_temp_table_name = ... # Optional: Specifies the temp table name in the catalog used for Tecton spines
Notes regarding some of these configuration options:
s3_path: (Defaults to a newly created bucket in the user’s region). S3 Path
that Athena writes its results to, and that Tecton uploads spines to. Must start
with s3://.
database: (Defaults to default). Name of the AWS Glue catalog Tecton
registers Athena tables in (both for spines and for Feature Views).
spine_temp_table_name: (Defaults to the empty string). Prefix for the Glue
table the SDK registers when a spine, as required by some
get_historical_features calls, is uploaded to S3 and registered in S3. This is
useful if multiple users use the SDK at the same time.
Required permissions
The environment in which the SDK is used must have the following permissions to AWS services:
- S3:
- Read and write access to the S3 path specified in
ATHENA_S3_PATH - Read access to the S3 bucket Tecton uses for the Offline Store
- Read and write access to the S3 path specified in
- Glue Catalog:
- Read and write access to the catalog specified in
ATHENA_DATABASE, includingglue:CreateTableglue:DeleteTable
- Read and write access to the catalog specified in
- Athena
- Full read access, including
athena:StartQueryExecutionathena:GetQueryExecution
- Full read access, including
Authentication
The authentication methods that are available for authenticating your environment with AWS are described here.
On-Demand Feature Views
If you use a Feature Service that depends on On-Demand Feature Views, they will be executed locally directly in the SDK’s client environment.