Aggregation Engine
Some of the most common features used by ML models are aggregation features. Tecton's Aggregation Engine is a distributed computation framework for incrementally building aggregation features from raw event data. Aggregation features are derived by calculating metrics over a window of time, such as averages, counts, max/min values, etc.
The Aggregation Engine optimizes both the feature engineering experience and the production performance of these features.
To learn how to use the Aggregation Engine, please refer to Using the Aggregation Engine.
Architecture Overview
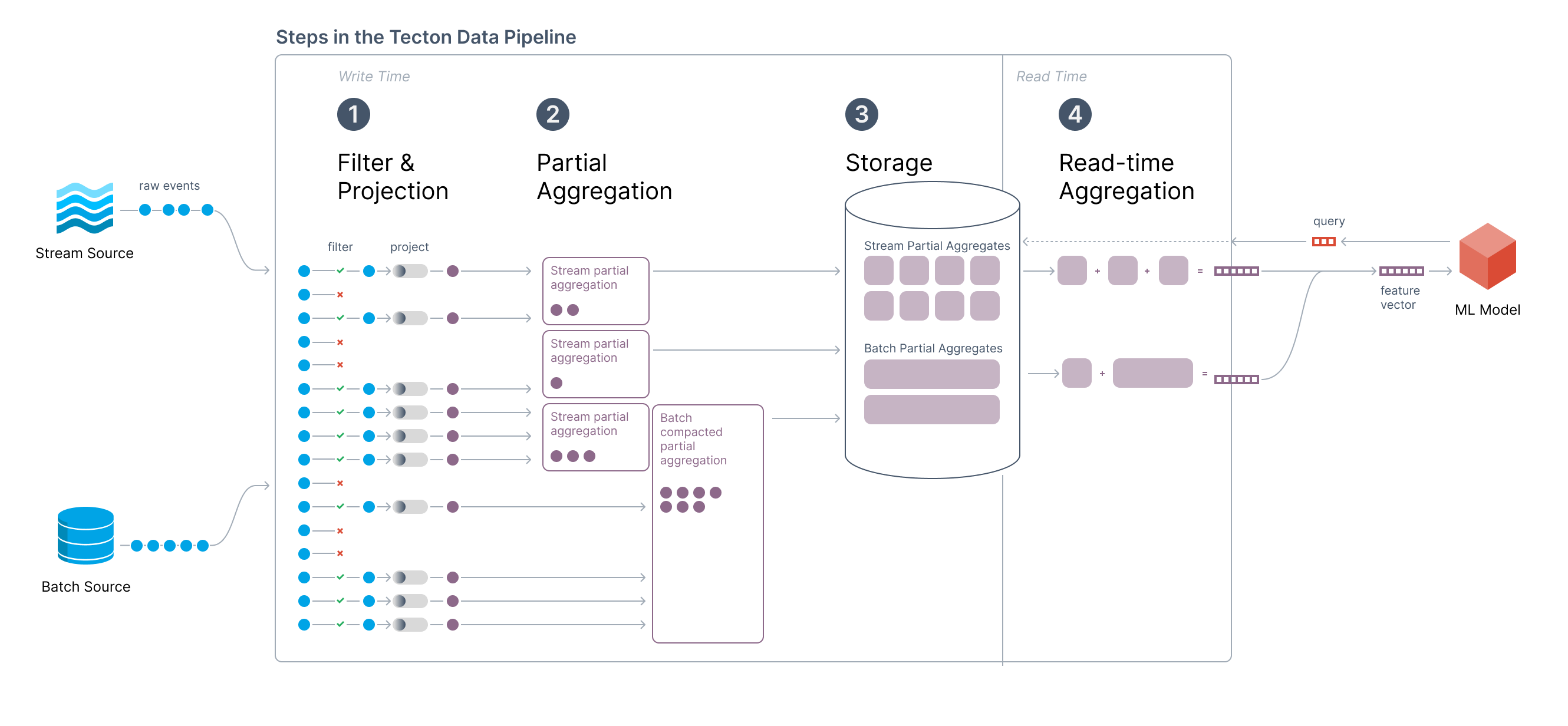
Benefits of the Aggregation Engine
Simplicity
- Simple UX: Defining online/offline-consistent, highly-performant and fresh features requires only a few lines of code
- Preprocessing Flexibility: You can aggregate raw data directly, or aggregate raw data that you filter / transform using standard Python or SQL
- Backfill Support: Streaming and Batch Features can be backfilled from batch data sources
- Data Source Agnostic: Aggregations are seamlessly supported across Batch, Stream or Push Data Sources
Performance & Efficiency
- Lifetime Window Support: You can aggregate a limited time window, or the entire life-time of data
- Low Latency Serving: Tecton optimizes the stored data to provide ultra-low latency serving, even for large time windows
- Streaming Memory Efficiency: Streaming aggregation features manage their state in Tecton's online store. As a result, they have a very limited memory footprint - even for arbitrarily large time windows. As a result, OOMs that you commonly run into with industry-standard streaming processors are a thing of the past.
- Online Storage Efficiency: Tecton's aggregation engine optimizes the data stored in the online store, significantly reducing the infrastructure cost
- Minimal Backfills: Backfills are done intelligently - Tecton only writes relevant data of the recent past to the online store.
Accuracy
- High Freshness: Time Window aggregations can be anchored to the "present" time, at which the feature data is requested. This allows you to fetch aggregation features that are fresh as of a few milliseconds
- Time Travel Compatible: When generating training data, Tecton's time travel capability ensures that you avoid online/offline skew
- Correctness Guarantees: Writing time window aggregations that can be executed online and offline consistently is hard and getting it wrong is easy. If you use Tecton aggregations, online/offline consistency and accuracy are guaranteed.