Reading Online Features for Inference via a Feature Output Stream
This feature is currently in Public Preview.
Introduction
Feature View Output Streams enable your application to subscribe to the outputs of streaming feature pipelines. Your application accesses these outputs via a stream sink.
As a Stream Feature View processes new events, the output values are written to the stream sink at the same time the values are persisted to the feature store.
Usage
Feature View Output Streams are designed to be used for asynchronous predictions, where model inference is triggered by newly arriving feature data.
Example workflow
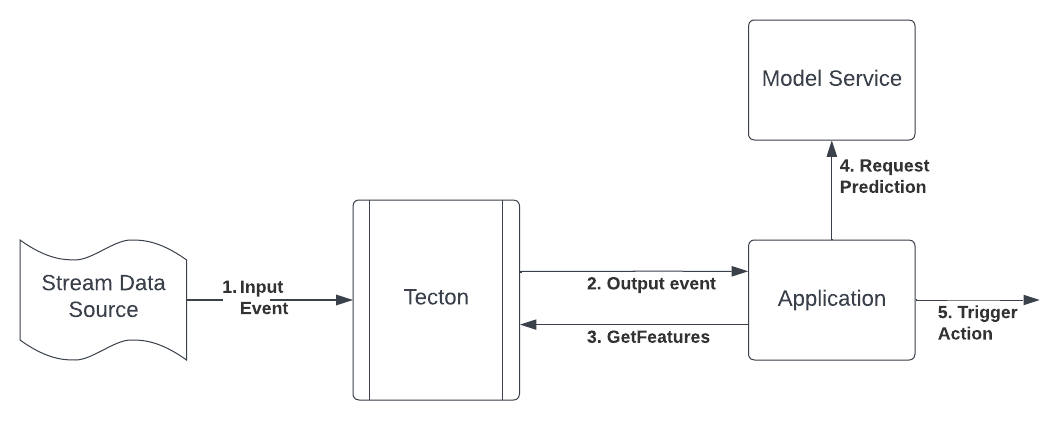
- New events arriving on the stream source are processed by Tecton.
- The application processes the record from the output stream. The record
contains metadata, such as the time the feature was updated, which the
application may use to determine if a new prediction is required. If so, the
application makes a
GetFeaturesrequest to retrieve the feature vector. - The application requests a new prediction using this feature vector from the Model Service.
- The application triggers an asynchronous action based on the prediction output.
For example, suppose you are developing a new system that sends promotion offers to users after they add items to their cart. Specifically, you want to send a promotional offer if the increase in conversion rate is at least 10%.
In Tecton, you define an add_item_to_cart Data Source and a
user_items_added_to_cart Feature View, which uses the data source. In your
application, you create logic for using Feature Output Streams.
The following steps illustrate the system’s workflow.
add_item_to_cartdetects a new event that was generated in the data stream.- The
user_items_added_to_cartFeature View processes the new event and the outputs of that processing are written to a Feature Output Stream sink at the same time the values are persisted in the feature store. - The application pulls from Feature Output Stream, and notices the event is
ready. Then, the application requests the full feature vector for this user,
by making a
GetFeaturesrequest. This request will return the lifetime purchase value and previous offers redeemed. - The application makes a request to the conversion model in the Model Service, which predicts how likely the user is to convert with and without a promotion.
- The application sends the promotion to the user, if the increase in conversion is above the 10% threshold.
Limitations
- Backfilled data is not be written to the Output Stream.
- An Output Stream can only be used, if in the Stream Feature View, one of the
following is true:
- Built-in aggregations are used (i.e. the
aggregationsparameter is set) and thestream_processing_modeparameter is set toStreamProcessingMode.CONTINUOUS. - Built-in aggregations are not used (i.e. the
aggregationsparameter is not set).
- Built-in aggregations are used (i.e. the
- When using built-in aggregates in a Stream Feature View (which are specified
in the
aggregationsparameter), the outputs do not include aggregated feature values. You must query theGetFeaturesendpoint to get the feature vector, which includes fully aggregated feature values.
Configuration requirements
- A Stream Feature View with online materialization enabled (i.e. the
onlineparameter is set toTrue). - A Kafka or Kinesis topic for which the Output Stream will write to.
- The Spark role configured for Tecton materialization jobs must have write access to this topic.
- For Kafka, the Tecton materialization jobs should either run in the same VPC as the Kafka stream, or use VPC peering.
Sample configuration
- Kinesis
- Kafka
@stream_feature_view(
source=ad_impressions_stream,
entities=[user],
mode="spark_sql",
online=True,
offline=True,
ttl=timedelta(days=365),
batch_schedule=timedelta(days=1),
feature_start_time=datetime(2022, 2, 1),
output_stream=KinesisOutputStream(
stream_name="feature-stream-name",
region="us-west-2",
include_features=True,
),
)
def user_impression_counts_noagg(ad_impressions_stream):
return f"""
SELECT
user_uuid as user_id,
1 as impression,
timestamp
FROM
{ad_impressions}
"""
@stream_feature_view(
source=ad_impressions_stream,
entities=[user],
mode="spark_sql",
online=True,
offline=True,
ttl=timedelta(days=365),
batch_schedule=timedelta(days=1),
feature_start_time=datetime(2022, 2, 1),
output_stream=KafkaOutputStream(
kafka_bootstrap_servers="bootstrap-server",
topics="kafka-topic",
include_features=True,
),
)
def user_impression_counts_noagg_kafka(ad_impressions_stream):
return f"""
SELECT
user_uuid as user_id,
1 as impression,
timestamp
FROM
{ad_impressions}
"""
Output schema
Events written to the output stream have the following schema:
version: str- Set to “1”. When the API is updated, this value will be incremented.producer: str- “tecton”.job_type: str- Always “stream” for now.feature_view_name: strfeature_view_id: strfeature_timestamp: str- Timestamp of written event in ISO date format, such as "2022-06-07T00:36:08.832793Z”.entity_keys: Dict[str,str]- Dictionary of entity keys (always populated)feature_values: Optional[Dict[str,str]]- Populated ifinclude_featuresis True.
Ensuring consistency
Online feature reads are eventually consistent. As a result, it’s possible that
the response from GetFeatures will not include the output record.
If you need to ensure consistency, compare the feature_timestamp value from
the output event with the effective_time field included in the feature vector
metadata response. Note that your request will need to set the
include_effective_times metadata option. If
effective_time < feature_timestamp, then you may retry the request.
Costs
Tecton does not charge for use of a Feature View Output Stream. However, you may incur infrastructure costs that result from activities such as:
- Processing events on your streaming infrastructure
- Needing to increase provisioning for Stream Feature View clusters
SDK reference
The Stream Feature View has a new parameter output_stream, which takes a
KafkaOutputStream
or
KinesisOutputStream.
If the feature view has online=true, then new events will be written to the
specified output_stream.