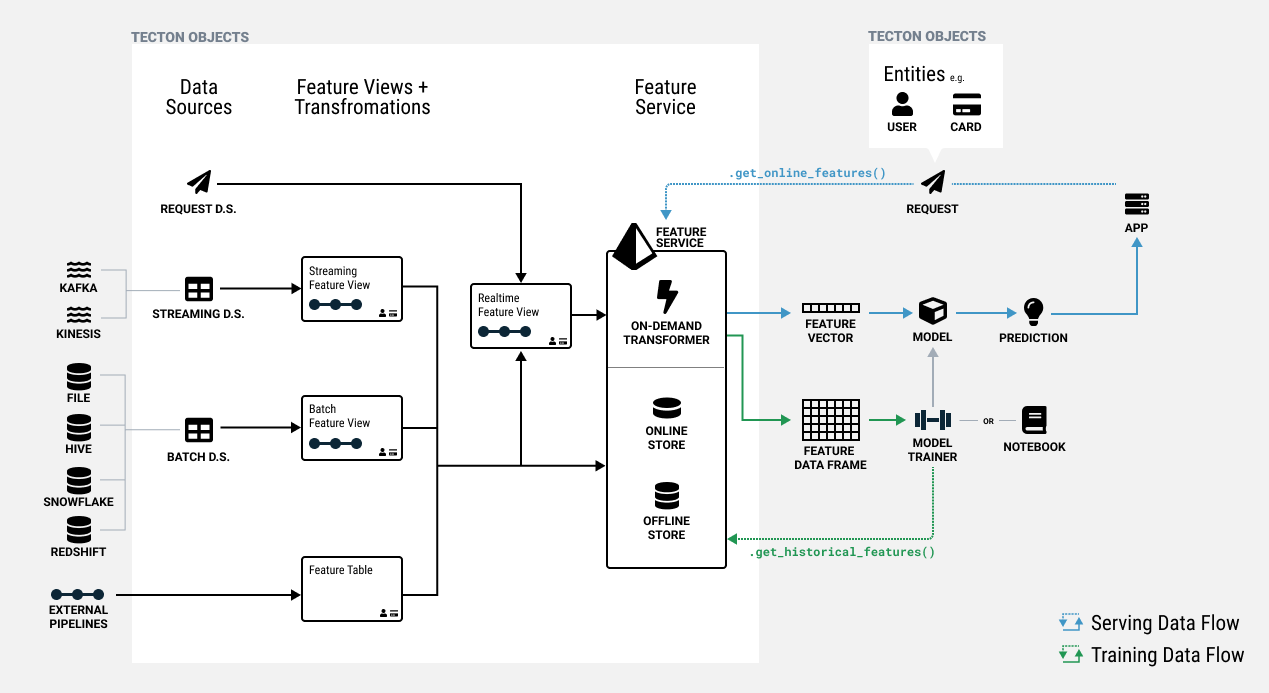
Feature Views
In Tecton, features are defined as a view on registered Data Sources or other Feature Views. Feature Views are the core abstraction that enables:
- Using one feature definition for both training and serving.
- Reusing features across models.
- Managing feature lineage and versioning.
- Orchestrating compute and storage of features.
A Feature View contains all information required to manage one or more related features, including:
- Transformation: A Feature View takes in one or more input sources and runs transformations to compute features. Sources can be Tecton Data Sources or in some cases, other Feature Views.
- Entities: The business entities that the features are attributes of such as Customer or Product. The entities dictate the join keys for the Feature View.
- Configuration: Materialization configuration for defining the orchestration and serving of features, as well as monitoring configuration.
- Metadata: Optional metadata about the features used for organization and discovery. This can include things like descriptions and tags.
The transformation and entities for a Feature View define the semantics of what the feature values truly represent. Changes to a Feature View's transformation or entities are therefore considered destructive and will result in the rematerialization of feature values.
Concept: Feature Views in a Feature Store
Types of Feature Views
There are 3 types of Feature Views:
- Batch Feature Views run transformations on one or more Batch Sources and can materialize feature data to the Online and/or Offline Feature Store on a schedule.
- Stream Feature Views transform features in near-real-time against a Stream Source, or Push Data Source, and can materialize data to the Online and Offline Feature Store.
- Realtime Feature Views run transformations at request time based on data from a Request Source, Batch Feature View, or Stream Feature View.
Feature View Compute Engines and Transformations
Every Feature View has a transformation type and associated
Compute Engine, controlled by the Feature
View's mode parameter.
Certain transformations are only compatible with specific Feature Views types due to the nature of the compute engines leveraged. The table below shows what transformation types and associated compute engines (e.g. Rift or Spark) are supported for each Feature View.
| Name | Rift | Spark |
|---|---|---|
| Batch Feature View | pandas, snowflake_sql, bigquery_sql, or python | spark_sql or pyspark |
| Stream Feature View | pandas or python | spark_sql or pyspark |
| Realtime Feature View | pandas or python | N/A |
When both Rift and Spark are enabled on the same cluster, Tecton selects the compute engine to use for specific Feature Views based on the Feature View's transformation type.
When using Python mode, the transformation will take dictionaries as inputs and is expected to output a dictionary.
When using Pandas mode, the transformation will take Pandas DataFrames as inputs and is expected to output a Pandas DataFrame.
Python transformations are faster in online environments because there is no added overhead of a Pandas DataFrame. However, they are slower in offline environments when executed across many rows because they can not take advantage of vectorized operations. The opposite is true of Pandas transformations.
As a result, for any online application we generally recommend using Pandas for Batch and Stream Feature Views and Python for Realtime Feature Views, because Realtime Feature Views directly affect online serving latencies.
If your features are used strictly in a batch prediction use case, we recommend using Pandas transformations everywhere.
Defining a Feature View
A Feature View is defined using an decorator over a function that represents a pipeline of Transformations.
Below, we'll describe the high-level components of defining a Feature View. See the individual Feature View type sections for more details and examples.
# Feature View type
@batch_feature_view(
# Pipeline attributes
sources=[source],
mode="<mode>",
# Entities and features
entities=[entity],
timestamp_field="<timestamp_field_name>",
features=[],
# Materialization and serving configuration
online=True,
offline=True,
batch_schedule=timedelta,
feature_start_time=datetime,
ttl=timedelta,
# Metadata
owner="<owner>",
description="<description>",
tags={},
)
# Feature View name and transformation
def my_feature_view(input_data):
return ...
See the API reference for the specific parameters available for each type of Feature View.
Registering a Feature View
Feature Views are registered by adding a decorator (e.g. @batch_feature_view)
to a Python function. The decorator supports several parameters to configure the
Feature View.
The default name of the Feature View registered with Tecton will be the name of
the function. If needed, the name can be explicitly set using the name
decorator parameter.
The function inputs are retrieved from the specified sources in corresponding
order. Tecton will use the function pipeline definition to construct, register,
and execute the specified graph of transformations.
Defining the Feature View Function
A Feature View defines one transformation function that is executed when the Feature View runs. It runs against data retrieved from external data sources. For details, see the Transformations section.
Interacting with Feature Views
The Tecton SDK provides a set of methods that allow you to interactively test features or generate training data in any Python environment, such as a Python notebook. See Reading Feature Data for details.