AggregationLeadingEdge
The AggregationLeadingEdge enum allows users to choose what timestamp they
would like Tecton to use for the leading edge of the aggregation window.
Note: If a user is upgrading a feature view to 1.0.0+, they are required to
explicitly set this parameter to AggregationLeadingEdge.LATEST_EVENT_TIME
since this is the default prior to 1.0.
Attributes
LATEST_EVENT_TIME: Default prior to 1.0: Tecton uses the latest event time of the stream to decide where to set the leading edge of all aggregation windows for that feature view.WALL_CLOCK_TIME: Default in 1.0: Tecton uses the wall clock time of the request on the feature server to decide where to set the leading edge of all aggregation windows for that feature view.
Concepts
Tile
A tile is a unit of compacted data used in Tecton's Aggregation Engine for efficiently computing and storing feature values. Tiles are partial-aggregate values that can be combined and finalized into aggregation results at query time. A tile may be a simple data type (like an integer for a count or sum) or a complex data structure (such as those used for approximate algorithms like HyperLogLog).
Tiles serve several key purposes in Tecton:
- They enable efficient storage and computation of aggregation features
- They allow Tecton to minimize the amount of data stored while maintaining the ability to compute accurate feature values
- They support both batch and streaming use cases by providing a consistent way to store partial results that can be combined later
For example, in a streaming use case, Tecton may store aggregation tiles representing 1-hour windows of data, rather than storing every individual event. When a feature value needs to be computed (like a 24-hour sum), Tecton can efficiently combine these 24 tiles rather than processing all the raw events.
A complete tile is a fixed-interval window of time that has fully elapsed. For example, with hourly tiles, a tile from 1:00-2:00 becomes complete at 2:00. The current in-progress interval (like 2:00-3:00 if querying at 2:30) is considered a partial tile and is not included in aggregations.
A partial tile is a fixed-interval window of time that has started but not yet fully elapsed. It represents the time window between the last complete tile and the current time.
For example, for hourly tiles, at 1:30pm, the latest complete tile is the 12pm-1pm tile. There will be a partial tile started at 1pm, but that tile is not yet complete. At 2pm, the tile is complete.
Partial tiles are not included in the aggregations. This eliminates skew between online and offline stores, as the offline store will always have an exact number of tiles. For example, if we're getting the last 7 days of data, the offline store will have exactly 7 days. The online store will have a window between the last complete tile and the current time. That data is not included in the aggregation, and instead, a full 7 days (or whatever specified time range) is pulled going back from the last complete tile.
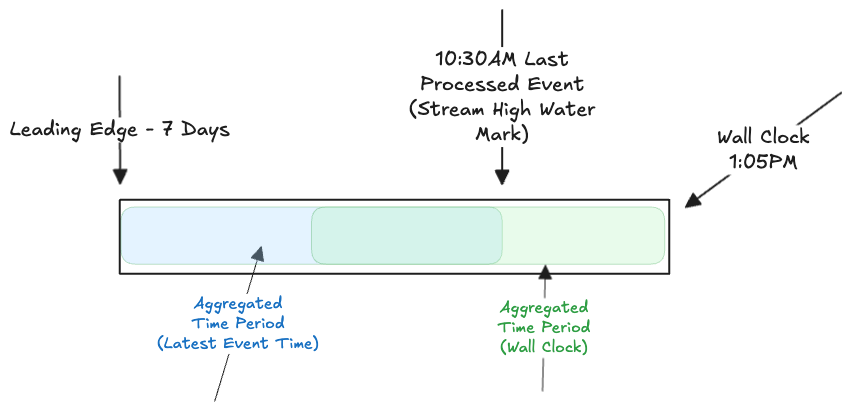
Stream High Watermark
The Stream High Watermark is the time of the last (most recent) processed event.
Having a watermark that is further in the past leads to "stale" data as the time between the watermark and the request time is longer. More events/data could have been in the stream during that time, but just not yet processed due to overhead or lag in stream processing.
The Stream High Watermark is only used when the feature view is using
AggregationLeadingEdge.LATEST_EVENT_TIME.
Pre-existing (< 1.0) Behavior: LATEST_EVENT_TIME
Existing system uses the stream high watermark, regardless of when you request data. If request time is 1pm, but watermark is 11:05am, the time window begins at 11am (because that's the last complete tile prior to the high watermark, assuming the aggregations are 1 hour tiles), not 1pm, and stretches back from there. This can lead to confusion as users may expect to see data going back from 1PM, and the ending time of the window will be further back then expected. If you look for leading edge -7 days, you would expect that to begin at 1pm, 7 days prior, but it will instead begin at 11am 7 days prior (which would be 7 days back from the LAST COMPLETE TILE prior to the stream high watermark).
Differences in the New (>= 1.0) Behavior: WALL_CLOCK
- Does not use Stream High Watermark.
- Starts at last complete tile EVEN IF the last processed event was further in the past, say 10:30am. So, if the aggregation interval is 1h, and the request is at 1:05pm and the last complete tile is 1pm: the window starts at 1pm.
- The window will include empty tiles if applicable, spanning the time between the last processed event and the request time. In the example above, with the last processed event happening at 10:30am, empty tiles would exist for 11am-12pm and 12pm-1pm.
- Default behavior beginning in version 1.0.
Example
In the following diagrams:
- the time period is
leading edge - 7days - the request time is
1:05pm - the last processed event is
10:30am - the interval is
1h
LATEST_EVENT_TIME
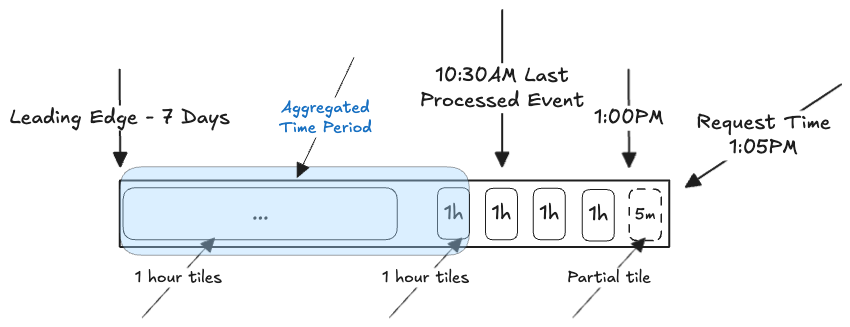
The time period aggregated will be 10:00am - 7 Days
WALL_CLOCK
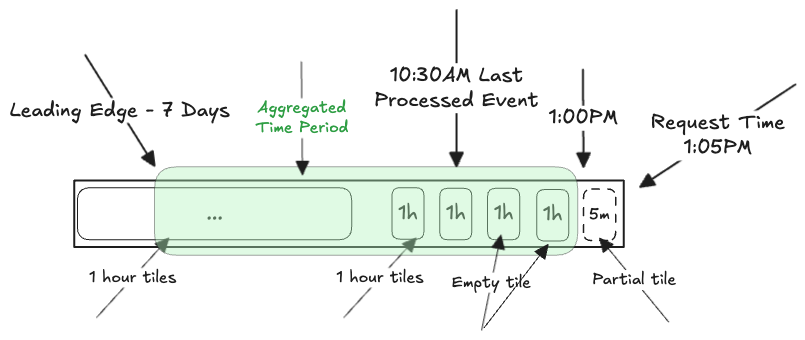
The time period aggregated will be 1:00pm - 7 Days
Continuous Mode
If you set StreamProcessingMode to CONTIUOUS, the behavior looks like this:
- No tiles are generated, so every event is aggregated at request time.
- For
WALL_CLOCK, the window begins at the request time. - For
LATEST_EVENT_TIME, the window begins at Stream High Watermark (most recent processed event).
For LATEST_EVENT_TIME, the time period aggregated will be 10:30am - 7 Days
For WALL_CLOCK, the time period aggregated will be 1:05pm - 7 Days
Example Comparison
Let's assume these parameters:
- Your stream is 30 minutes late, and the latest stream event that has arrived
in the online store is
2024-07-29T2:31:00Z - The online feature vector read request is for a 1-hour sum aggregation
(
SUM(col)). Read Request was made at timestamp:2024-07-29T3:00:00Z - With the following event time data:
| Timestamp | col | Included in aggregation using WALL_CLOCK_TIME | Included in aggregation using LATEST_EVENT_TIME |
|---|---|---|---|
| 2024-07-29T1:32:00Z | 1 | no | yes |
| 2024-07-29T1:55:00Z | 1 | no | yes |
| 2024-07-29T2:10:00Z | 1 | yes | yes |
| 2024-07-29T2:32:00Z | 1 | no (late) | no |
| 2024-07-29T2:41:00Z | 1 | no (late) | no |
| 2024-07-29T2:49:00Z | 1 | no (late) | no |
| 2024-07-29T2:55:00Z | 1 | no (late) | no |
The sum using WALL_CLOCK_TIME is 1, while the sum using LATEST_EVENT_TIME
is 3. The reason for this is 30 minutes of data, i.e., 4 data points after 2:31
AM that are not counted towards a full 1-hour aggregation using the
WALL_CLOCK_TIME timestamp because the stream is delayed by 30 minutes.
FAQ
- Why is wall clock time the default behavior?
- This improves most users' out-of-the-box experience, to align with common use
cases, and significantly reduce read costs. The default,
aggregation_leading_edge=AggregationLeadingEdge.WALL_CLOCK_TIME, uses the current request timestamp as the aggregation window's leading edge, which is often more intuitive and useful in real-time scenarios and leads to much cheaper reads than usingLATEST_EVENT_TIME.
- Why can't I directly set the
aggregation_leading_edge=WALL_CLOCK_TIMEfor Stream Feature Views applied with Tecton SDK < 1.0?- This change may cause differences in the aggregate feature values served.
- For example, a 2 minute lagged stream will always compute a 2 min-lagged 30 minute aggregation meaning that the 30 minute window will be missing 2 min worth of data. If we use the latest event time, both the offline and online aggregations will always compute a full 30 minute window of data. This issue becomes worse as the stream delay becomes larger.
- Do we have any plans to match this behavior for the offline store?
- Yes, Tecton has plans to add functionality to resolve some data delay related skew to the offline retrieval code path.
- I want to experiment with the different aggregation leading edge strategies,
how can I do this?
- You can experiment by controlling the behavior of the aggregation leading
edge at the request time, which will overridden the Stream Feature View
configuration. The
aggregation_leading_edgeparameter can be overridden at the request level as follows:
- You can experiment by controlling the behavior of the aggregation leading
edge at the request time, which will overridden the Stream Feature View
configuration. The
NOTE: The override functionality is scheduled for deprecation in a future release to align with our long-term goal of simplifying the system and improving cost-efficiency.
$ curl -X POST http://<your_cluster>.tecton.ai/api/v1/feature-service/get-features\
-H "Authorization: Tecton-key $TECTON_API_KEY" -d\
'{
"params": {
"feature_service_name": "mockdata_feature_service",
"join_key_map": {
"user_id": "user_1",
},
"requestOptions": {
"aggregationLeadingEdge" = "AGGREGATION_MODE_WALL_CLOCK_TIME" or "AGGREGATION_MODE_LATEST_EVENT_TIME"
},
"workspace_name": "prod"
}
}