Detect Feature Drift with Arize
Tecton integrates with Arize for AI observability, this page describes the integration points and provides code examples for each.
For ML use cases, Arize offers a robust solution for monitoring and managing machine learning model performance in production, specifically by tracking data quality, performance, and drift -- both in model output, and in the features supplied as inputs.
Tecton integrates with Arize to provide Feature Drift and Model Performance analysis. Tecton's feature values and predictions can be served to Arize for logging and monitoring.
Process Overview
Training data is used to build a model, and then uploaded onto Arize to create the training baseline that establishes expected feature and prediction distributions. When a model makes predictions using features from Tecton, the event identifier, the resulting prediction, and input features are logged in Arize. At a later time, when the events are labeled, the ground truth associated with each event is uploaded to Arize. This enables Arize feature and model drift tracking by comparing values to the training baseline.
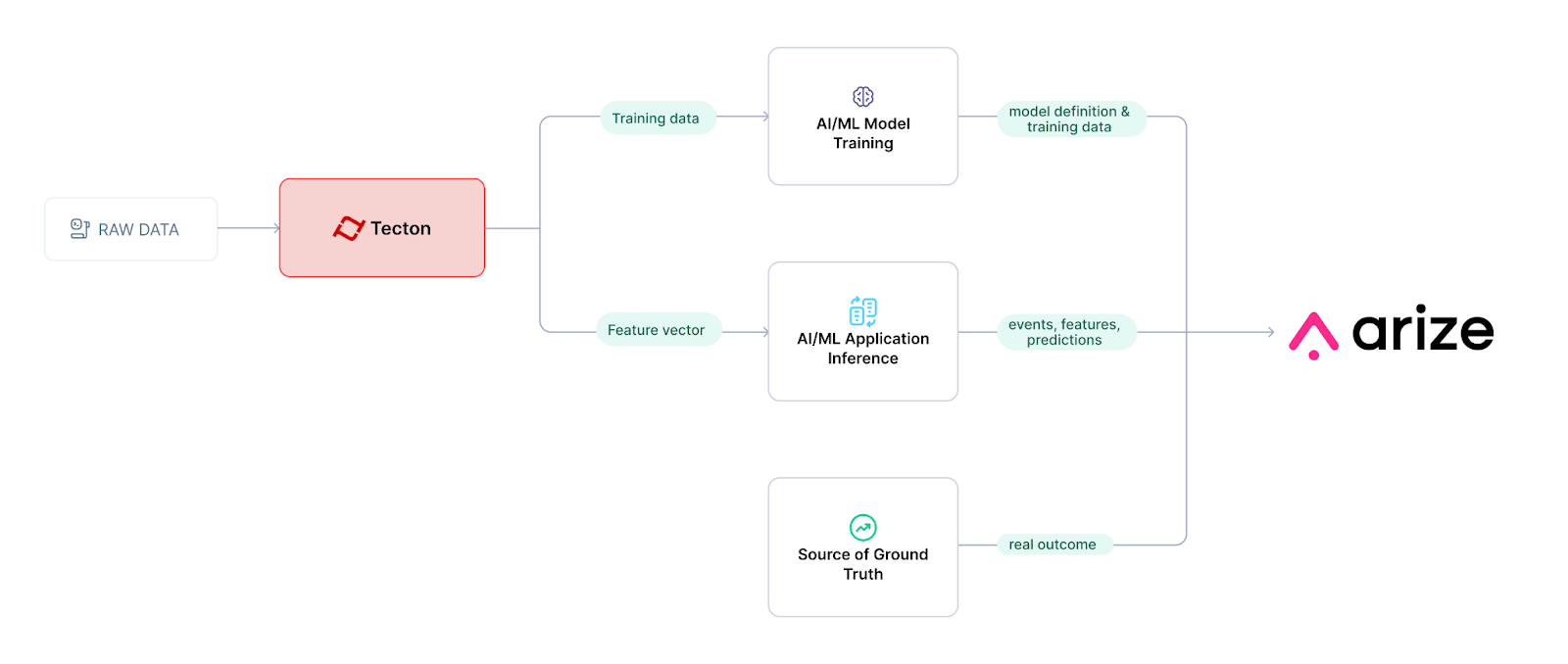
The example below uses Tecton training data and inference time logging with Arize.
The process is divided into the following steps:
- Prepare training Data
- Register and baseline the model in Arize
- Log inference to Arize in a production application
- Log ground truth
- See proactive ML monitoring in action
1. Prepare Training Data
In a notebook, use the Feature Service method get_features_for_events to
retrieve time-consistent training data from your Feature Service. Depending on
the volume of the data, you can run training
data generation
using local compute or larger remote engines like Spark or EMR.
Given a dataframe of training events (labeled or not), get_features_for_events
enhances each event with time-consistent feature values. Training data needs to
be time consistent to prevent initial feature drift in production. This means
retrieving feature values exactly as they would have been calculated at the time
of each training event.
training_data = fraud_detection_feature_service.get_features_for_events(training_events)
Here's a sample of the resulting training_data:
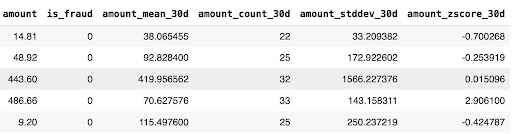
This training data is then used to train and validate an ML model in a ML development platform, and this is the point where Arize logging is integrated into the process.
2. Register and Baseline the Model in Arize
Next, log the model and training data with Arize to create the baseline for the model training data and its outputs.
Arize code integrates directly into the model training code and runs wherever and whenever training is run. This might be in a notebook or a scheduled training script that is used when a model is ready to be deployed to production.
First, define the model schema:
# define schema of the training and prediction data
arize_schema = Schema(
actual_label_column_name="is_fraud",
prediction_label_column_name="predicted_fraud",
feature_column_names=input_columns, # model inputs
prediction_id_column_name="transaction_id",
timestamp_column_name="timestamp",
tag_column_names=["user_id"],
)
Let Arize know what the baseline data looks like for this model, so it has a reference to compare new feature values for drift.
To prepare the baseline, the trained model is used to calculate predictions for
the baseline training data, the true outcome of the event (fraud_outcome) is
added along with the model prediction (predicted_fraud):
input_data = training_data.drop(["transaction_id", "user_id", "timestamp", "amount"], axis=1)
input_data = input_data.drop("is_fraud", axis=1)
input_columns = list(input_data.columns)
# calculate predictions
predictions = model.predict(input_data)
# add prediction to training set
training_data["predicted_fraud"] = predictions.astype(float)
# add outcome column
training_data.loc[(training_data["is_fraud"] == 0), "fraud_outcome"] = "Not Fraud"
training_data.loc[(training_data["is_fraud"] == 1), "fraud_outcome"] = "Fraud"
display(training_data.sample(5))
Here's an excerpt of the baseline training data:
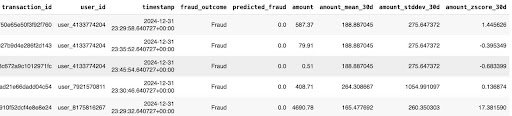
And here's how to log the model and training data:
response = arize_client.log(
dataframe=training_data, # includes event columns, training features and outcomes
schema=arize_schema,
model_id="transaction_fraud_detection",
model_version="v1.0",
model_type=ModelTypes.BINARY_CLASSIFICATION,
metrics_validation=[Metrics.CLASSIFICATION],
environment=Environments.TRAINING,
)
The environment parameter defines whether this is training, validation or production data. Validation data along with its predictions is also logged in the same fashion.
3. Log Inference to Arize in a Production Application
ML Applications are deployed in different ways, but they will all follow the same 2-step process:
- Retrieve feature vector from Tecton for a new request
- Get a prediction from the model using the feature vector
The following sequence of code simulates the process of an ML application. The
hard-coded current_transaction holds some inputs needed to retrieve features
from Tecton, and also includes identifying columns like the transaction_id,
user_id, and timestamp which are needed for logging the event on Arize:
current_transaction = {
"transaction_id": "57c9e62fb54b692e78377ab54e9d7387",
"user_id": "user_1939957235",
"timestamp": "2025-04-08 10:57:34+00:00",
"amount": 500.00,
}
Retrieve online features from Tecton:
# feature retrieval for the transaction
feature_data = fraud_detection_feature_service.get_online_features(
join_keys={"user_id": current_transaction["user_id"]}, request_data={"amount": current_transaction["amount"]}
)
# feature vector prep for inference
data = [feature_data["result"]["features"]]
features = pd.DataFrame(data, columns=columns)[X.columns]
# inference
prediction = {"predicted_fraud": model.predict(features).astype(float)[0]}
When a model makes predictions using features from Tecton, the prediction result along with the input features and event identifiers are logged to Arize as an event. This enables Arize feature and model drift tracking by comparing values to the training baseline.
Add this code to each prediction:
# we put together the full event
publish_data = [current_transaction | features.to_dict("records")[0] | prediction]
# we add the yet unknown actuals as None
publish_data = [publish_data | {"is_fraud": None, "fraud_outcome": None}]
# and log it in Arize as production data
response = arize_client.log(
dataframe=pd.DataFrame(publish_data),
schema=arize_schema,
model_id="transaction_fraud_detection",
model_version="v1.3",
model_type=ModelTypes.BINARY_CLASSIFICATION,
metrics_validation=[Metrics.CLASSIFICATION],
environment=Environments.PRODUCTION,
)
Notice that the environment parameter is set to PRODUCTION.
4. Log Ground Truth
Since this is a fraud detection example, the ground truth is whether the
transaction is fraudulent or not. In most cases this information is unknown
until some arbitrary time later, for example when the cardholder reports a
transaction as fraudulent. This is the reason that Arize models include the
prediction_id_column_name which indicates which data column uniquely
identifies an event. Take advantage of Arize's asynchronous logging of the
actual outcome column by using the prediction_id_column_name to associate a
logged prediction with its corresponding ground truth.
Example:
# log ground truth, only include actual label and prediction id columns
arize_schema = Schema(
actual_label_column_name="is_fraud",
prediction_id_column_name="transaction_id",
)
event_update = [
{
"is_fraud": 1.0,
"transaction_id": "57c9e62fb54b692e78377ab54e9d7387",
},
]
response = arize_client.log(
dataframe=pd.DataFrame(event_update),
schema=arize_schema,
model_id="transaction_fraud_detection",
model_version="v1.0",
model_type=ModelTypes.BINARY_CLASSIFICATION,
metrics_validation=[Metrics.CLASSIFICATION],
environment=Environments.PRODUCTION,
)
5. See Proactive Monitoring in Action
Now it's possible to leverage Arize to provide feedback on model performance, and get early alerts on the feature data pipeline. This feedback can then be used to adjust feature engineering in Tecton and/or retrain the model.
Here's what Arize reports, where prediction drift is clearly visible:
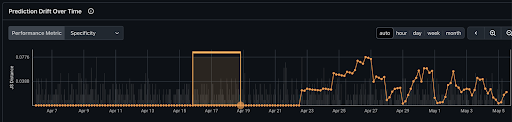
Understand which features are drifting:
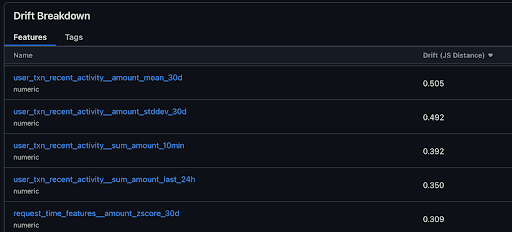
Examine individual feature drift:
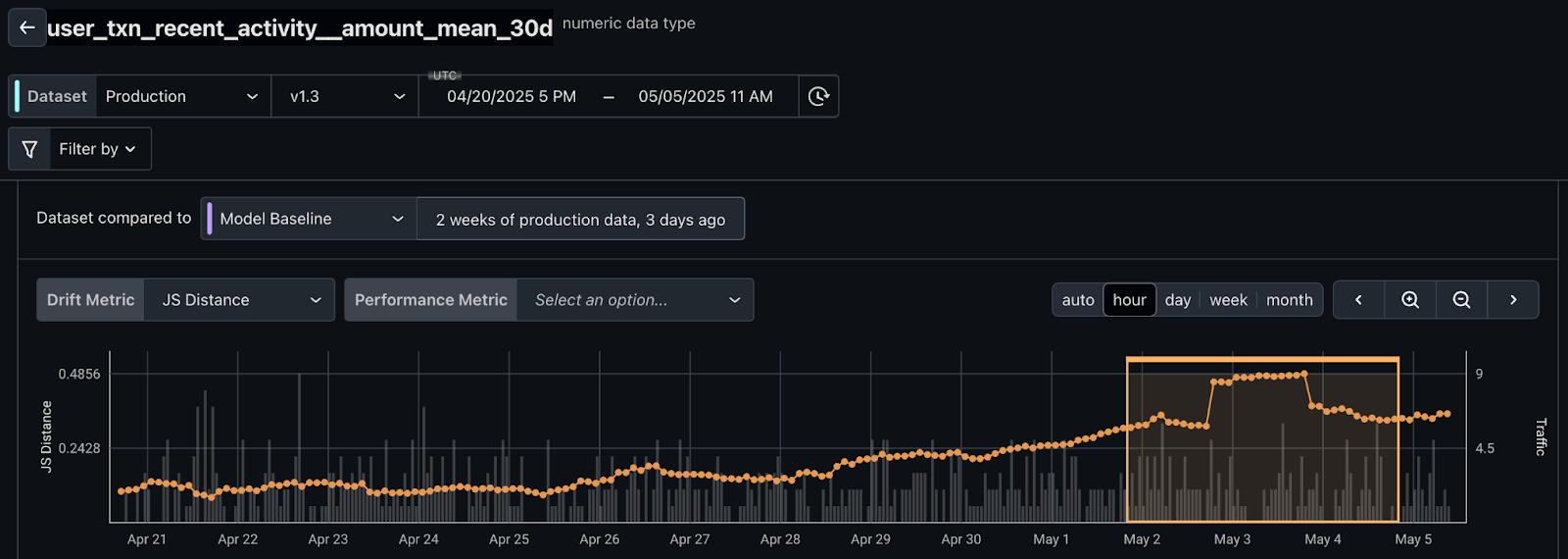
The result is a great monitor of the model performance - ensuring ML model does not degrade over time - and an early warning system for issues in the upstream data or skew in the features.
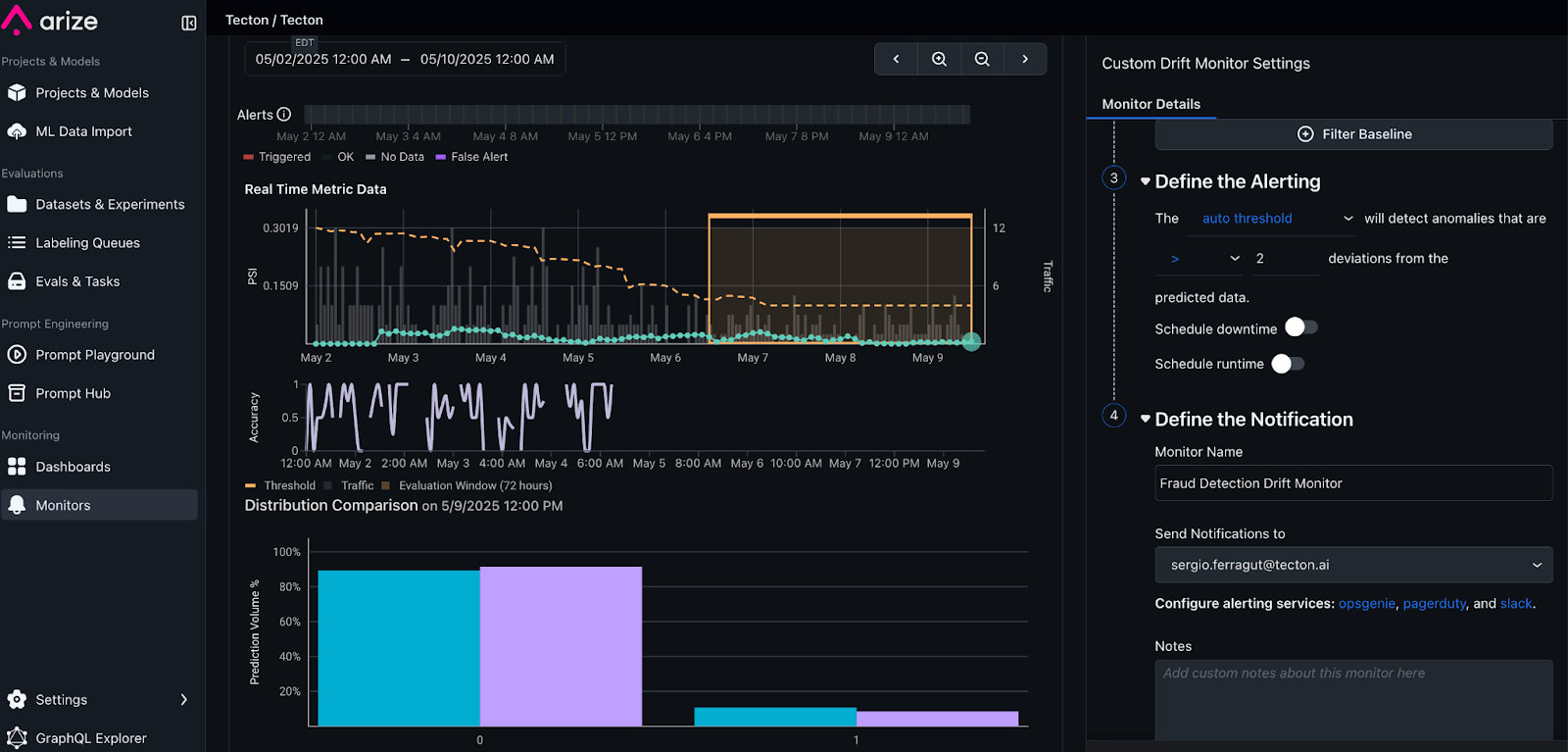
Set up Arize monitors, to be notified whenever any of the features or model distributions drift beyond a threshold.