Tecton on Databricks in Google Cloud Deployment Model
Overview
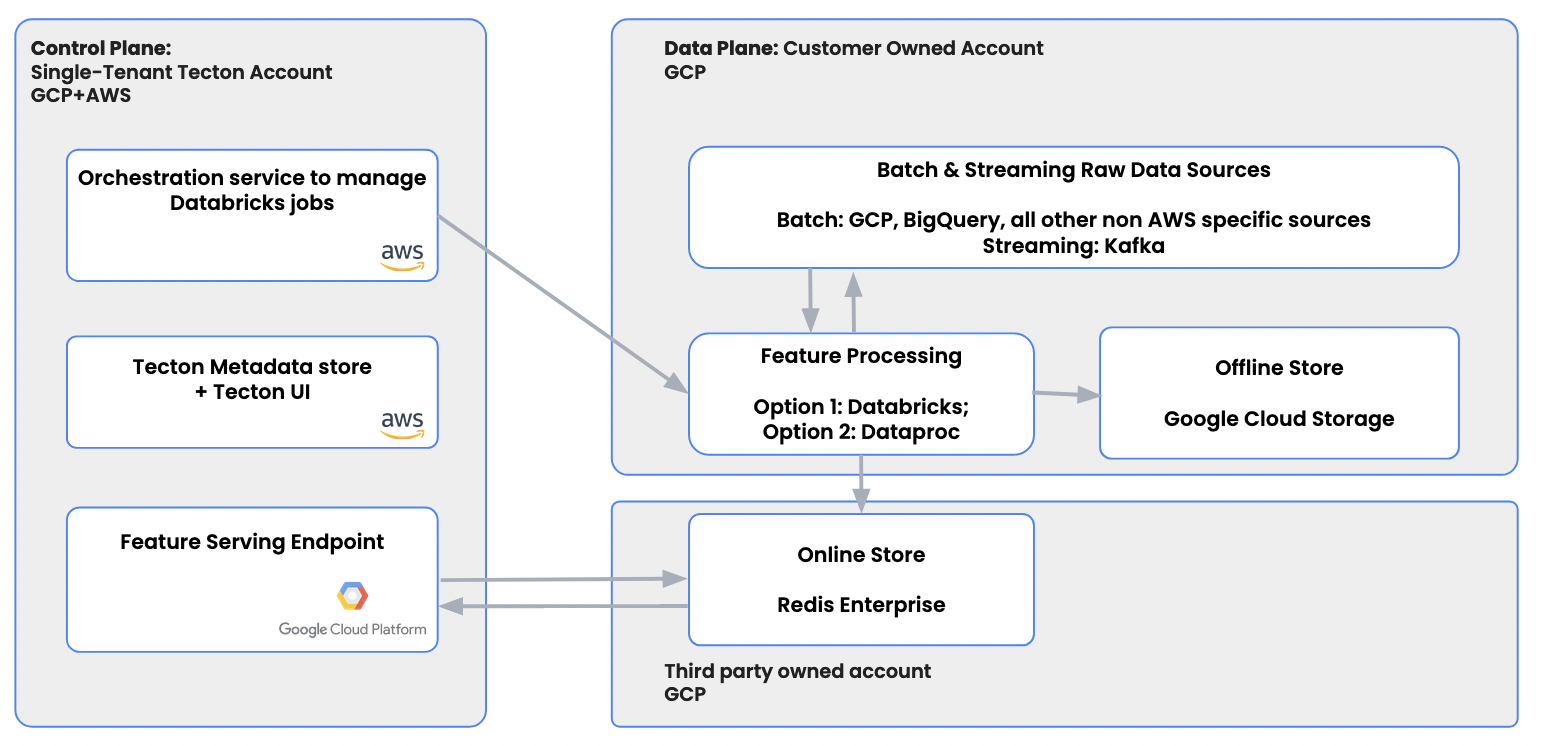
The Google Cloud deployment architecture consists of a control plane, a data plane, and a serving plane:
-
The control plane lives in a single-tenant Tecton AWS account and is operated by Tecton to guarantee core services such as data pipeline orchestration and metadata management.
-
The data plane is where data is processed and lives entirely in the customer-owned Google Cloud Project. It connects to raw data sources and processes them within your account. It does not host any proprietary services from Tecton.
-
The serving plane serves online features to applications running in production. The serving plane is deployed to a single-tenant Google Cloud Project managed by Tecton.
This architecture ensures data security and compliance while leaving operational overhead to Tecton. It enables you to receive constant updates and get access to new product features seamlessly. And it guarantees that Tecton engineers can independently maintain and resolve any urgent issues with your features, 24/7.
The architecture is illustrated in the following diagram.
Before you get started
Decide on a name for your deployment
(e.g. mycompany-production). This name will become part of the URL that is
used to access your Tecton UI (mycompany-production.tecton.ai). The name must
be less than 22 characters.
Decide on your primary region
You will select a region (e.g. us-west1).
Confirm your Tecton control plane service account.
Your Tecton control plane service account is provided by your Tecton deployment
specialist. It will look like
tecton-<deployment>-control-plane@<tecton-deployment>.iam.gserviceaccount.com.
Configure Compute Platform
Configure Online Storage
Tecton supports both Redis and Bigtable as options for online storage.
See Connecting Redis or Connecting Bigtable.
Configure Offline Storage and Permissions
Tecton requires the following steps for setup:
1. Create a Cloud Storage Bucket (where Tecton will write feature data) in the data plane project
Tecton will use a single Cloud Storage bucket to store all of your offline materialized feature data.
To set this
up, create a bucket in
your data-plane project
called tecton-[DEPLOYMENT_NAME]-dataplane (e.g. tecton-mycompany-production-dataplane).
Ensure the bucket's region is the same as the region in which you would like to
deploy Tecton (e.g. us-west1)
2. Grant your Spark jobs permission to read your data sources and write to your bucket.
Create a service account and grant it the "Storage Object Admin" role on the bucket created above.
This service account should also be granted access to your data sources. For example, to read from Bigquery, grant the account the "Bigquery Data Viewer" role.
3. Grant Tecton access to the bucket created above, and to run Spark jobs with your desired service account.
Tecton needs access to the data plane bucket for ensuring data pipeline integrity, cleaning up unused feature data, and storing some forms of logging of Tecton services in the control plane. Access to this service account for these purposes is restricted to automated processes in the Tecton account. Grant the Tecton control plane service account the following permissions on the data plane bucket created above:
storage.buckets.get
storage.buckets.update
storage.objects.create
storage.objects.delete
storage.objects.get
storage.objects.getIamPolicy
storage.objects.list