Constructing Training Data
Overview
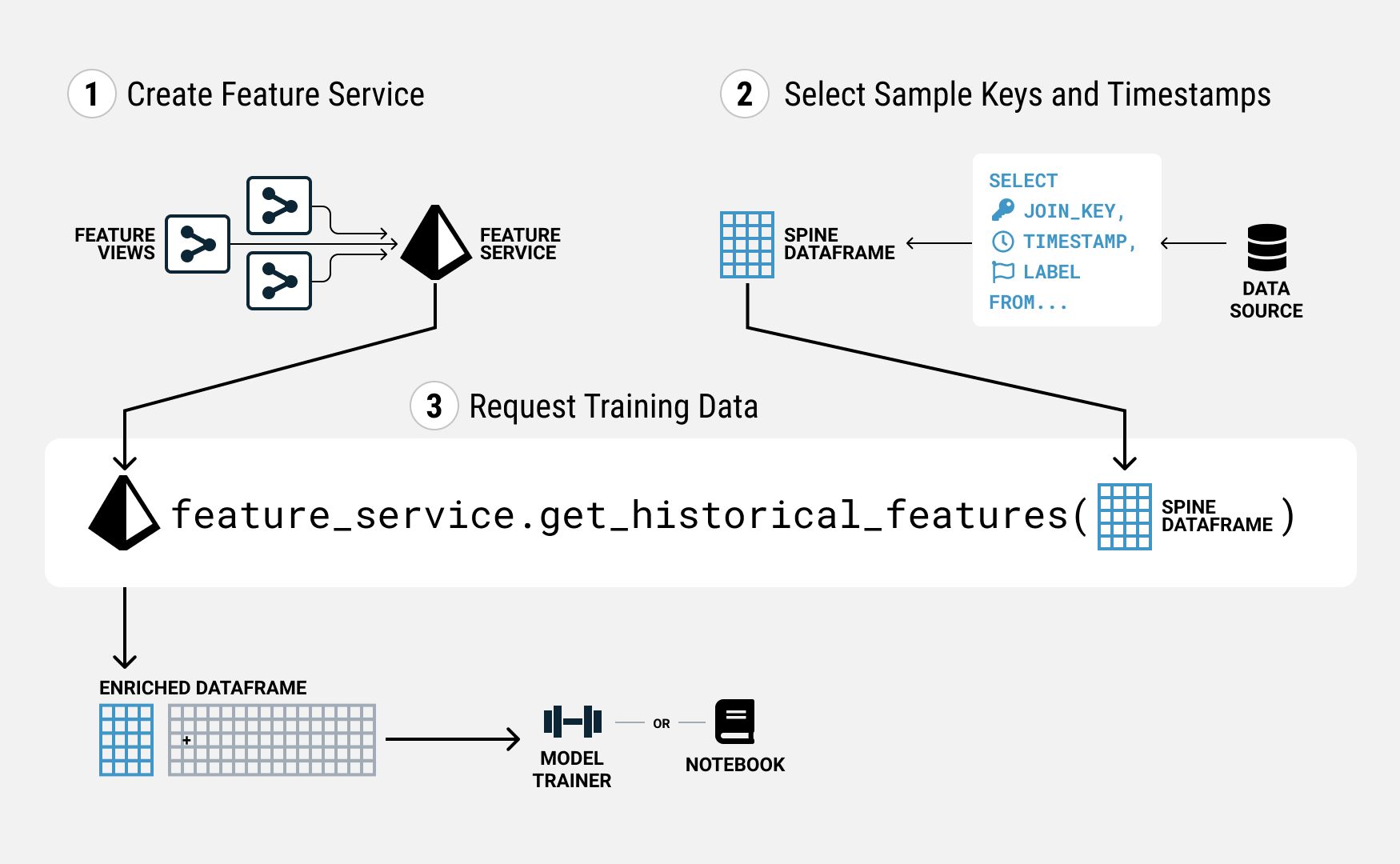
Tecton makes it easy to correctly create training data from your features. Constructing training data in Tecton involves three main steps:
- Creating the feature service that assembles the features you want, if you do not already have one.
- Selecting the keys and timestamps for each sample you want in your training data. We call this the spine.
- Requesting the training data from the Feature Service by giving it the spine.
Pre-requisites
- Feature Views – you need to have at least one Feature View, where the feature transformations you want are defined.
- Data Sources – you need to have at least one Data Source, from which your Feature Views will source data.
Before We Start: A Note on Point-in-time Correctness
You may have noticed that Tecton's training data generation API requires specifying a timestamp key for each sample. This timestamp is needed to produce what we call point-in-time correct feature values.
Why is this important? When training a model, data from before the prediction generation time is fair game, but data from after that moment should not be included. After all, at prediction time, you only have information from the past. Your models should be trained under this constraint as well. Failing to do so will lead to inflated offline performance metrics that the model will not achieve online.
Let's consider an ads click through rate use case.

If you want to use the prediction to make a decision when you are about to show an ad, then the timestamp should be the ad impression time. Note that prediction generation timestamps are different per sample! This per-sample point-in-time correct feature value generation is fairly tricky to implement. Fortunately, this works out of the box with Tecton.
Different prediction scenarios will require a different choice for the timestamp, and the choice depends heavily on your modeling approach. We will discuss this further in section 2.2.
1. Creating a Feature Service
In Tecton, a Feature Service is used both to serve features to production models, and to create training dataset for model training. You can create a Feature Service by writing a definition file.
Let's imagine you have created a number of different Feature Views for this
modeling task. Pulling them together is as simple as importing them and listing
them under features in your Feature Service definition.
ad_ctr_feature_service = FeatureService(
name="ad_ctr_feature_service",
description="A FeatureService providing features for a model that predicts if a user will click an ad.",
tags={"release": "production"},
owner="matt@tecton.ai",
features=[
user_ctr_7d,
user_click_counts,
user_impression_counts,
user_ad_impression_counts,
user_distinct_ad_count_7d,
],
)
For every Feature View you want to include, import them into your Feature
Service definition file, and list it under the features key. Once it is ready,
save it, and run tecton apply to create the Feature Service.
Next, let's generate a list of samples and timestamps (as known as a spine) which we will pass to the Feature Service.
2. Selecting sample keys and timestamps
Given a list of sample keys, and a timestamp for each key, Tecton's Feature Service will return all the feature values for that sample as they were at the time you specified. As we mentioned earlier, this key is critical for preventing future signals from leaking inappropriately into training data where they do not belong.
2.1 How do we get that timestamp?
Let's imagine we have two tables for our ads click through rate task:
- A time-series table of ad impression events
ad_impressions, with auser_id,ad_id, and atimestamp - A time-series table of ad click events
ad_clicks, again with auser_id,ad_id, and atimestamp
Using this data, we want to estimate the likelihood that a user will click a given ad in the 30 mins after it was shown.
In our spine, we need to have:
- The entity keys - i.e. the
user_idad_idpair - The timestamp – in this case, this should be the timestamp of the ad impression event
- Optionally, the label - in this case, this would be whether there was an ad
click event within 30 mins of the timestamp for the same
user_idad_idpair. In a training scenario, you'll need the label to train your model, however, this field is optional for retrieving features from Tecton.
Thus, a spine generation query might look like this.
SELECT
ad_impressions.user_id,
ad_impressions.ad_id,
ad_impressions.timestamp,
(
ad_clicks.timestamp IS NOT NULL AND
(JULIANDAY(ad_clicks.timestamp) - JULIANDAY(ad_impressions.timestamp)) * 1440 < 30
) as label
FROM ad_impressions
LEFT JOIN ad_clicks
ON ad_impressions.user_id = ad_clicks.user_id AND ad_impressions.ad_id = ad_clicks.ad_id;
Which might generate a spine that looks like this:
| user_id | ad_id | timestamp | label |
| 1 | 1001 | 2021-05-28 10:00:00 | 1 |
| 1 | 1002 | 2021-05-28 10:10:00 | 0 |
| 2 | 1001 | 2021-05-28 10:23:00 | 1 |
A spine like this, passed to the Feature Service as a dataframe, will enable you to leverage Tecton's point-in-time correct joins to full effect. We will discuss this more in section 3.
When building a spine with Tecton on Snowflake, you can use the
query_snowflake() function, that is provided in
Connecting Snowflake Notebooks,
to query against one or more Snowflake tables and/or views.
2.2 Choosing the Prediction Time Context
To choose the right timestamp, it is important to think through the time context in which your model will make a prediction. For example:
- In a credit card fraud use case, the prediction time context might be right before you would have charged the credit card. Activities post transaction shouldn't be used, since it would not have been available at the time the card is charged.
- In a matchmaking use case in a dating app, the prediction time context should be right before the recommendation was made. The matched users might exchange messages after, but that information would not have been there when the recommendations were made.
If you have an event that corresponds with the moment of prediction generation, that timestamp will work great. More generally, event tables in your data system are a good place to look for an appropriate timestamp. If you do not have event records at the right granularity, you may have to find a proxy or do some rearchitecting to take advantage of point-in-time correct joins.
Ultimately, the correct spine generation query is dependent on your framing of the modeling problem. A different problem framing will require a different set of queries and joins.
2.3 How Tecton uses the Timestamp
Under the hood, Tecton is tracking feature values and how they change over time. When given a timestamp in the training data generation request, we perform a lookup for each individual key and reconstruct the feature values as they would have been at the requested time.
Note that point-in-time correctness requires more than a global snapshot. Instead, we collect features for each join key according to its timestamp.
3. Requesting Training Data
You can generate your training data using FeatureService you defined above by
passing the spine table as a dataframe to the Feature Service using the
get_historical_features method.
spine = execute_query(...)
fs = tecton.get_feature_service("ad_ctr_prediction_service")
training_data = fs.get_historical_features(spine, timestamp_key="timestamp", from_source=True)
training_data contains the join keys, timestamps, and values for all the
features in the Feature Service, and any other columns that were in spine.
Tecton then joins all of the relevant feature values for each row in your spine
dataframe, and passes that back to you so that you can train your models.
If you would like to save this dataset for re-use later, or to share it with
your team, just set the save parameter to True in the
get_historical_features() call.
training_data = fs.get_historical_features(spine, timestamp_key="timestamp", save=True)
Converting the training data into a Snowpark DataFrame and use it with a DataFrameWriter
This section applies to Tecton on Snowflake, only.
Convert the DataFrame returned by get_historical_features() to a Snowpark
DataFrame:
training_data_snowpark = training_data.to_snowflake()
Using the Snowpark DataFrame, you can access its write property to create a
Snowpark
DataFrameWriter
object. With this object, you can call the save_as_table() and
copy_into_location() methods to save the data in the Snowpark DataFrame to a
Snowflake table and to an external file, respectively. The following example
shows a call to save_as_table():
training_data_snowpark.write.save_as_table("<table name>", mode="overwrite")
Using a Snowpark object (such as a DataFrame or DataFrameWriter) in a
notebook requires that Snowpark be installed in the notebook.
To install Snowpark, refer to the Connecting Snowflake Notebooks page.